Creating Glue Crawlers via Terraform
Scroll DownManaging your resources in AWS
In this article we will see how we can create and manage AWS Glue Crawler resource using infrastructure as code (IaC). IaC is now an industry standard and is crucial for managing your resources in a reliable and reproducible way. The resources we set up can be created and managed using a variety of IaC tools but in this article we will focus on Terraform. At the end of the article we will provide an example using Terraform due to its strong open source community and multi-cloud compatibility.
AWS Glue
As we all know that AWS Glue is a fully managed ETL (extract, transform, and load) AWS service. One of its key abilities is to analyze and categorize data. We can use AWS Glue crawlers to automatically infer database and table schema from your data stored in S3 buckets and store the associated metadata in the AWS Glue Data Catalog.
What are Glue Crawlers?
- A program that connects to your data source (S3, DynamoDB, MongoDB, JDBC etc.) to scan your data and creates metadata tables in Glue Data Catalog.
- Crawlers can scan multiple data sources in a single run.
- Once completed, it will create tables in Data Catalog.
- Further, these tables can be used by AWS services like Athena, ETL jobs, etc. to perform various operations.
How Crawlers work?
- Step 1: Classifies the data - to determine the format, schema and associated properties of the raw data.
- Step 2: Groups the data - Based on the classifications made, it groups the data into tables.
- Step 3: Writes Metadata - After grouping the data into tables, crawlers write metadata into Data Catalog.
When you define a crawler, you choose one or more classifiers that evaluate the format of your data to infer a schema. When the crawler runs, the first classifier in your list to successfully recognize your data store is used to create a schema for your table. You can use built-in classifiers or define your own. You define your custom classifiers in a separate operation, before you define the crawlers. AWS Glue provides built-in classifiers to infer schemas from common files with formats that include JSON, CSV, and Apache Avro.
The metadata tables that a crawler creates are contained in a database when you define a crawler. If your crawler does not specify a database, your tables are placed in the default database. In addition, each table has a classification column that is filled in by the classifier that first successfully recognized the data store.
If the file that is crawled is compressed, the crawler must download it to process it. When a crawler runs, it interrogates files to determine their format and compression type and writes these properties into the Data Catalog.
If your crawler runs more than once, perhaps on a schedule, it looks for new or changed files or tables in your data store. The output of the crawler includes new tables and partitions found since a previous run.
IAM roles and policies
This is one of the most useful parts to manage with an IaC tool, especially if your stack includes additional resources such as Glue jobs that also require permissions. In our example, the Glue crawler will require a role with permissions to access S3 and create Glue tables.
Terraform Example
The following example allows you to create the Glue Crawler from S3 path.
We will now create our Glue crawler, which will create and manage our Glue tables. The following main.tf is created under a module directory so that we can group resources together and reuse this group later, possibly many times.
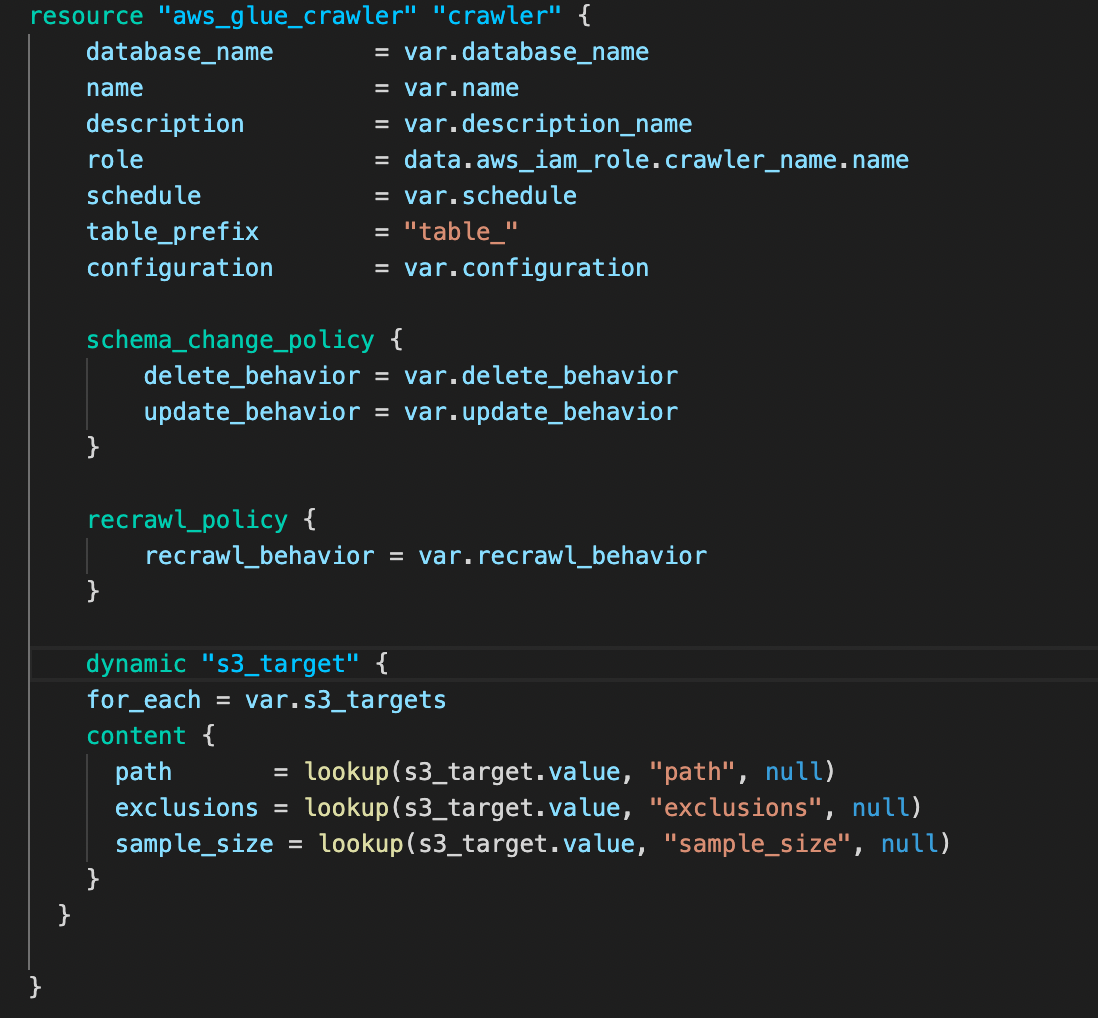
The above snippet explains how we can define our Glue Crawler under "aws_glue_crawler" resource type and make use of the variables defined under vars.tf file.
schema_change_policy and recrawl_policy are optional arguments that can be used in the configuration.
schema_change_policy - Policy for the crawler's update and deletion behavior.
delete_behavior- (Optional) The deletion behavior when the crawler finds a deleted object. Valid values:LOG,DELETE_FROM_DATABASE, orDEPRECATE_IN_DATABASE. Defaults toDEPRECATE_IN_DATABASE.update_behavior- (Optional) The update behavior when the crawler finds a changed schema. Valid values:LOGorUPDATE_IN_DATABASE. Defaults toUPDATE_IN_DATABASE.
recrawl_policy - A policy that specifies whether to crawl the entire dataset again, or to crawl only folders that were added since the last crawler run.
recrawl_behavior- (Optional) Specifies whether to crawl the entire dataset again or to crawl only folders that were added since the last crawler run. Valid Values are:CRAWL_EVERYTHINGandCRAWL_NEW_FOLDERS_ONLY. Default value isCRAWL_EVERYTHING.
dynamic block
A dynamic block acts much like a for expression, but produces nested blocks instead of a complex typed value. It iterates over a given complex value, and generates a nested block for each element of that complex value.
- The
for_eachargument provides the complex value to iterate over.
Since the for_each argument accepts any collection or structural value, you can use a for expression or splat expression to transform an existing collection.
The iterator object (s3_target in the example above) has two attributes:
keyis the map key or list element index for the current element. If thefor_eachexpression produces a set value thenkeyis identical tovalueand should not be used.valueis the value of the current element.
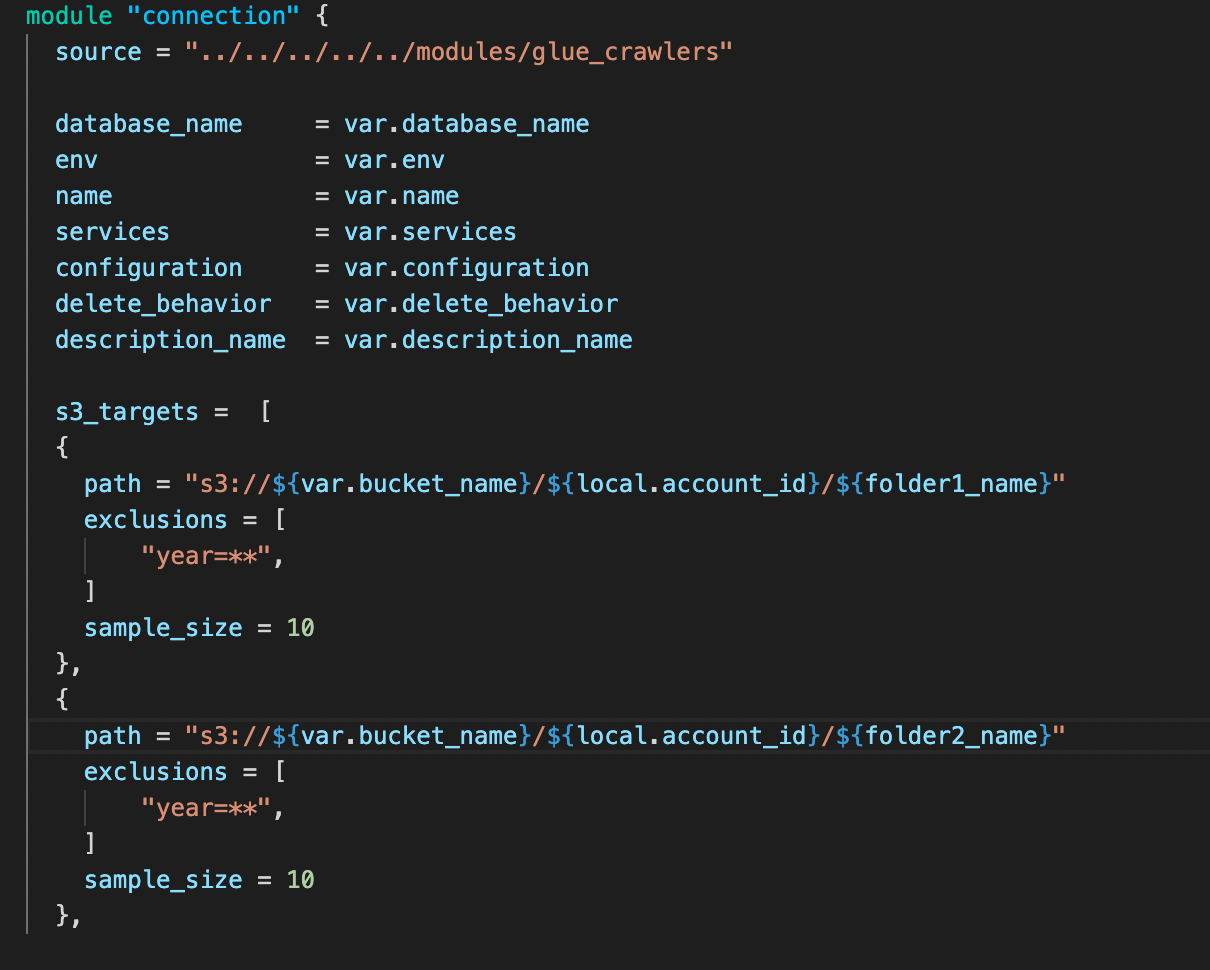
The above snippet is where we make use of the module that we created in the previous step. Under the module "connection", we are using a source argument in a module block tells Terraform where to find the source code for the desired child module.
Under s3_targets block, we are doing the following tasks:
- path - we are providing the path to the Amazon S3 target folder where we have to perform our crawl operations
- exclusions - meaning to exclude a list of glob patterns used to exclude from the crawl.
- sample_size - sets the number of files in each leaf folder to be crawled when crawling sample files in a dataset. If not set, all the files are crawled. A valid value is an integer between 1 and 249.
Similarly, we can add more S3 folder paths as per our convenience to crawler through the folders that we wish to use.
Creating your resources
Finally, to see what resources Terraform will create for you, you can run terraform plan to see the execution plan. To actually create the resources you can run terraform apply and see the changes on the AWS Console.
Conclusion
Overall, we can make use of Terraform IaC to spin up a resource within no time and play around with the different sets of options and get to know better of the resource. In this article, we were able to create Glue Crawlers from S3 target and see how we can make use of different options to achieve our end result.
View Comments