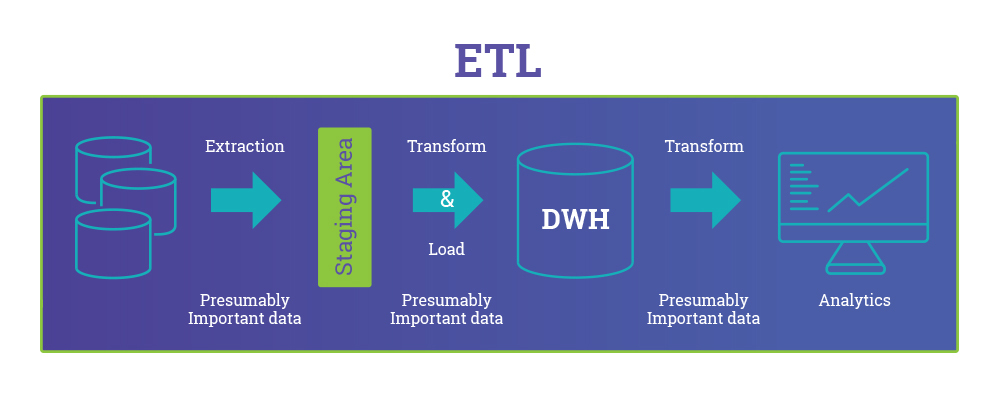
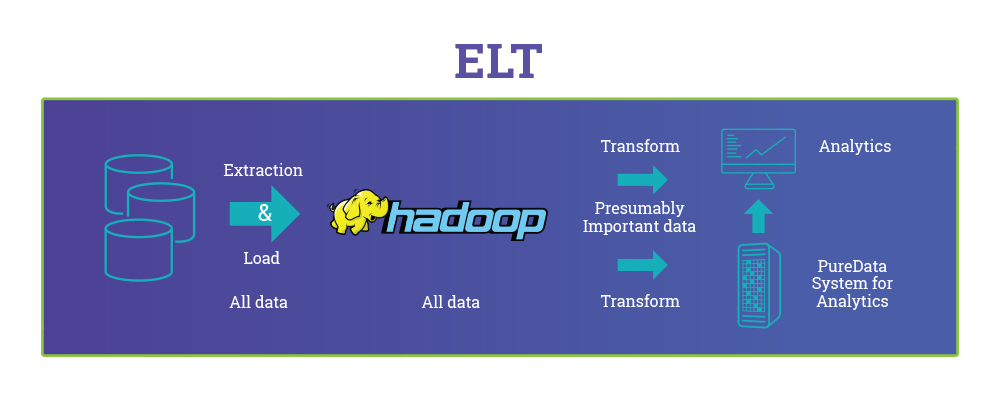
Yes our pipeline is ELT and not ETL, Extract, Load and Transform is the new Extract, Transform and Load and this post ETL vs ELT: The Difference is in the How on Dzone makes a good case of which to use when, to know the difference at a glance, below are sample diagrams from the article showing ETL and ELT pipeline difference.
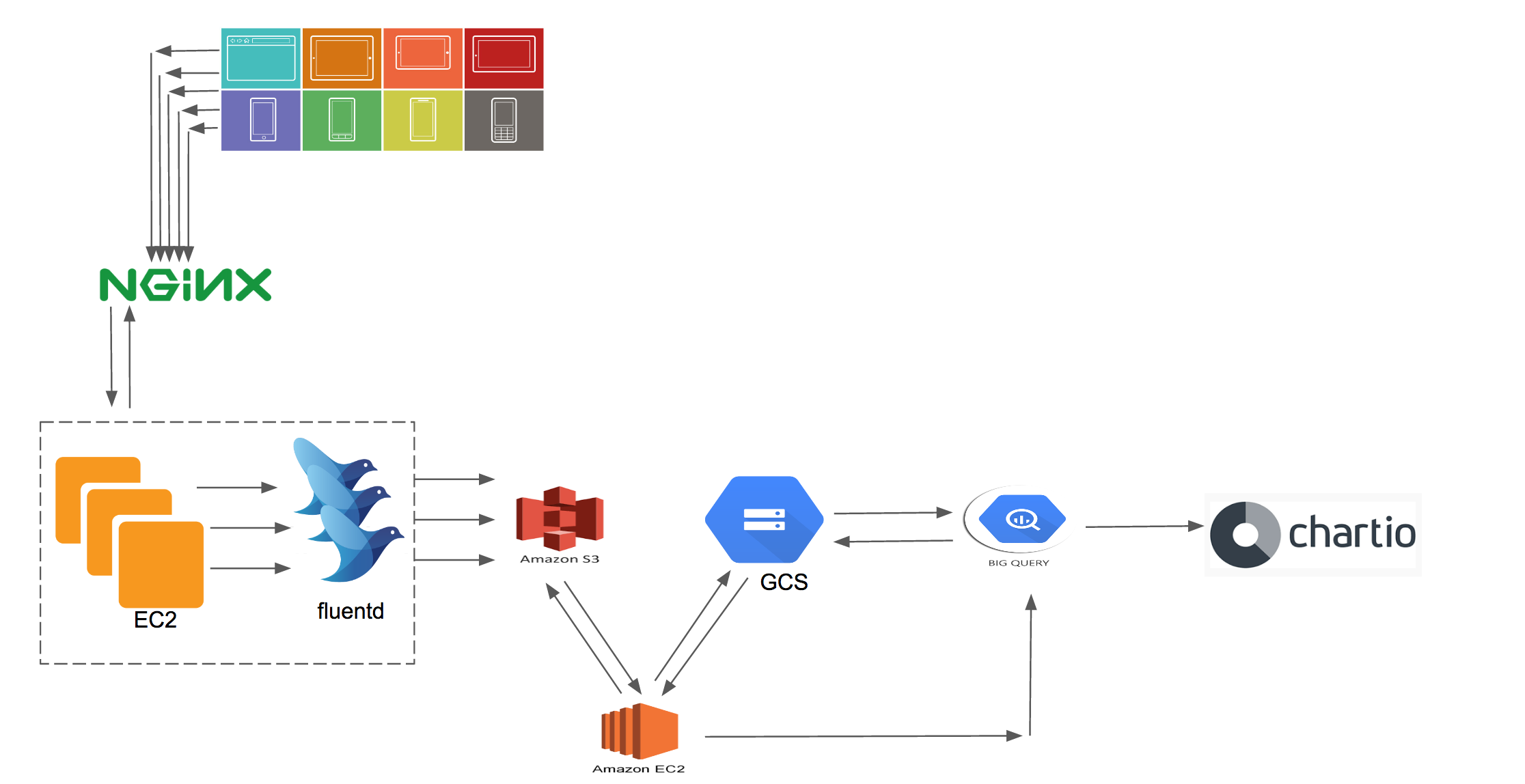
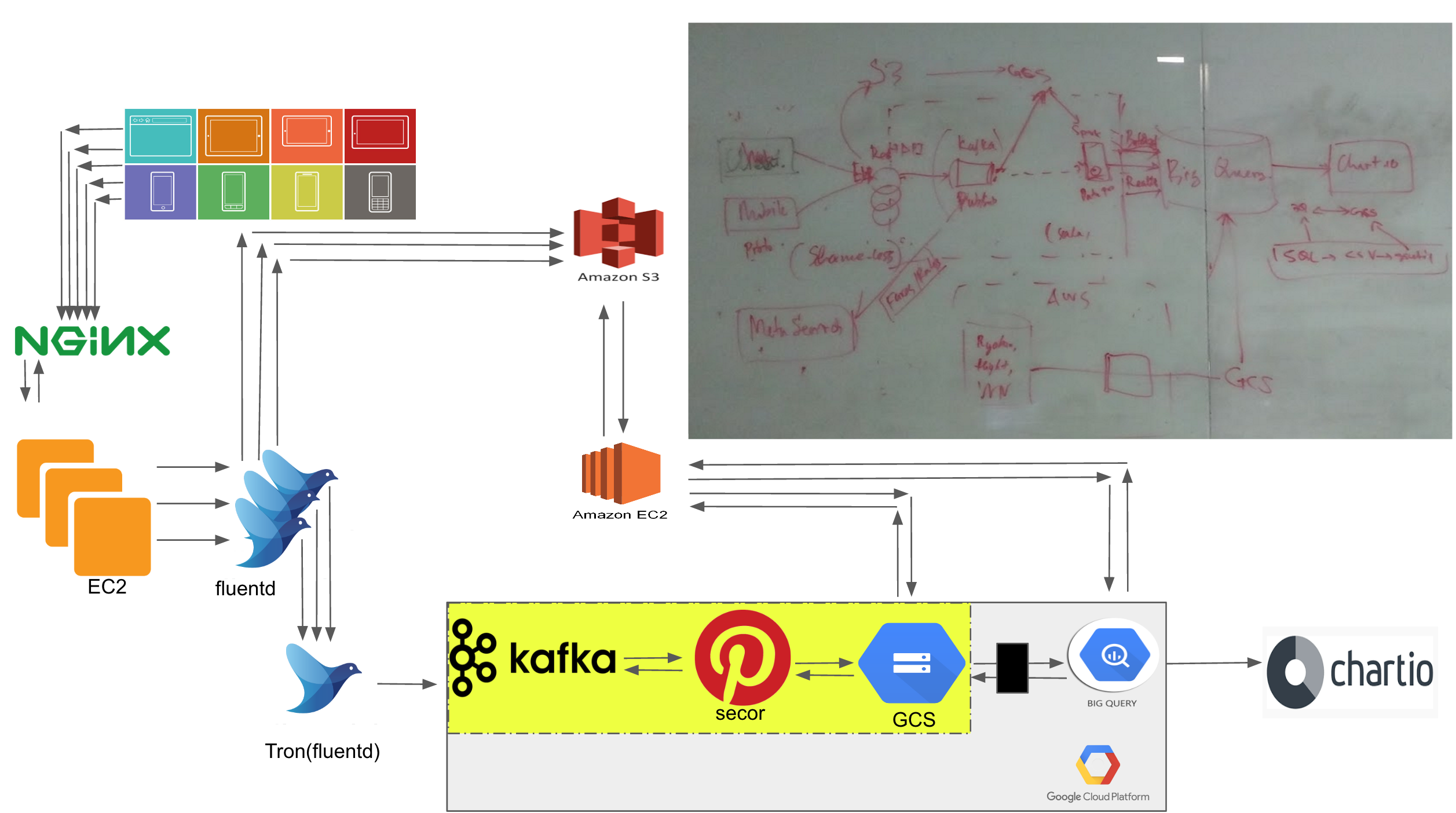
Our Initial Pipeline design was based on leveraging fluentd and Amazon S3 storage. From there on we would migrate the data into Google Cloud Storage for the purpose of importing the data into Big Query. Though this setup had served us well for over a year, it had its limitations that we managed along. The major drawback to this solution was to move the data to Big Query in time even though the process to import data was fast, we were bound by the windowing of the data due to the roll over of the file. To make it further clear, a file in fluentd can be rolled over by time and size, depending whichever limit it hits first. In theory and something we saw happening was if the file size would hit the limit before the time limit the new file would roll into the next hour and only uploaded when either it hits the rollover time limit or the size. Due to this the data imports for every hour would have to be scheduled at the 40th minute of the next hour to make sure all the data at least from the previous hour was uploaded. One does argue over why not just push the data into GCS directly, at the time we created the pipeline fluentd didn't have a plugin, and even now its not an officially supported fluentd plugin unlike for S3. Even if we were to upload the data to GCS, it still wouldn't resolve the issue of file rollover window, which was the bottleneck. Below is a diagram showing the pipeline design.
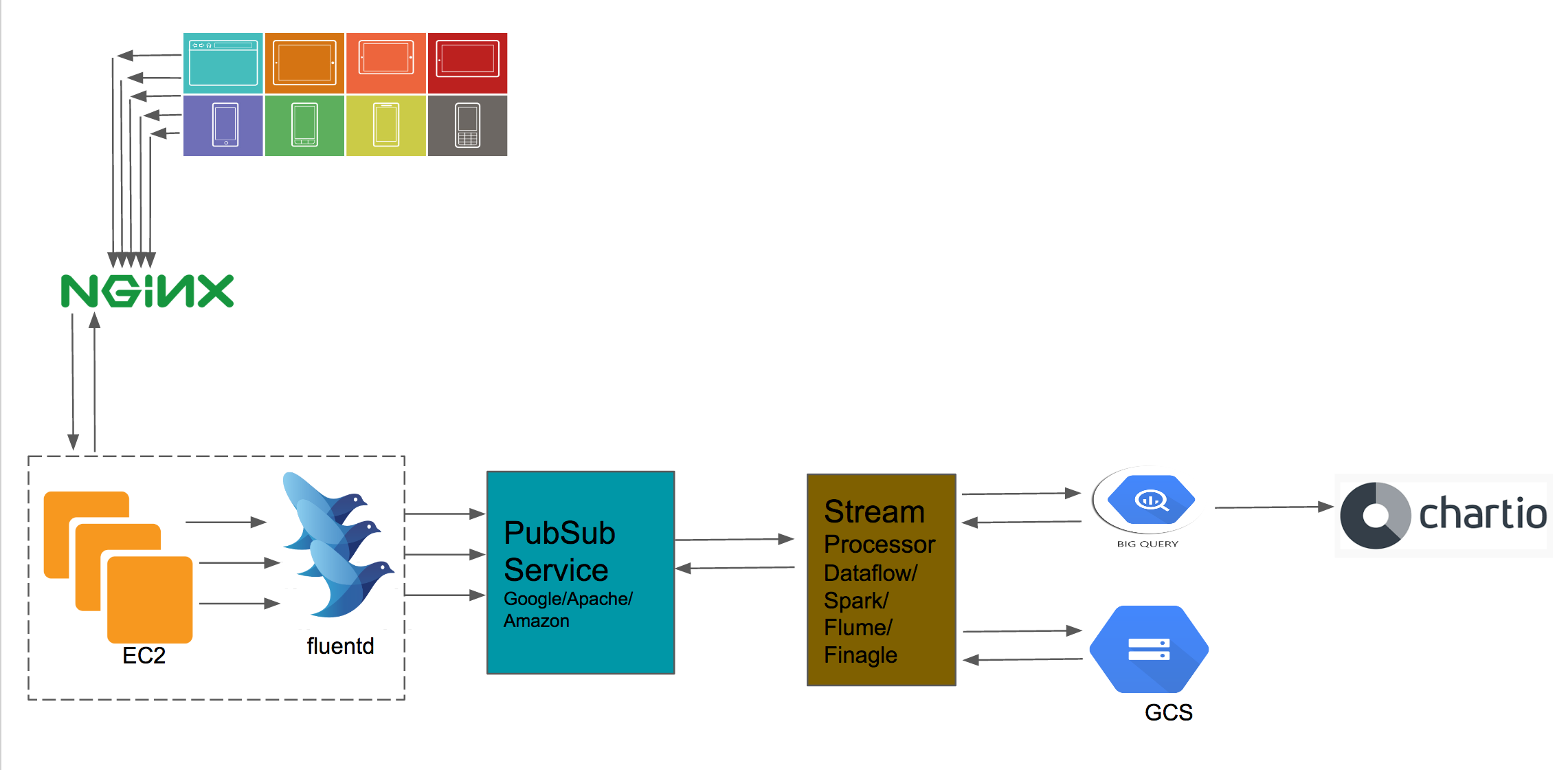
To counter the above mentioned problem, we decided to move our data to a Pub/Sub based stream model, where we would continue to push data as it arrives. As fluentd is the primary tool being used in all our servers to gather data, rather than replacing it we leveraged its plugin architecture to use a plugin to stream data into a sink of our choosing. Initially our inclination was towards Google PubSub and Google Dataflow as our Data Scientists/Engineers use Big Query extensively and keeping the data in the same Cloud made sense. The inspiration of using these tools came from Spotify’s Event Delivery – The Road to the Cloud. We did the setup on one of our staging server with Google PubSub and Dataflow. Both didn't really work out for us as PubSub model requires a Subscriber to be available for the Topic a Publisher streams messages to, otherwise the messages are not stored. On top of it there was no way to see which messages are arriving. During this the weirdest thing that we encountered was that the Topic would be orphaned losing the subscribers when working with Dataflow. PubSub we might have managed to live with, the wall in our path was Dataflow. We started off with using SCIO from Spotify to work with Dataflow, there is a considerate lack of documentation over it and found the community to be very reserved on Github, something quite evident in the world of Scala for which they came up with a Code of Conduct for its user base to follow. Something that was required from Dataflow for us was to support batch write option to GCS, after trying our hand at Dataflow to no success to achieve that, Google's staff at StackOverflow were quite responsive and their response confirmed that it was something not available with Dataflow and streaming data to BigQuery, Datastore or Bigtable as a datastore was an option to use. The reason we didn't do that was to avoid high streaming cost to these services to store data, as majority of our jobs from the data team are based on batched hourly data. The initial proposal to the updated pipeline is shown below.
After exhausting our efforts on Google's PubSub and Dataflow we decided to use the biggest player in this realm, Kafka. We run our Kafka cluster on Google Dataproc cluster (since writing of this post we have moved our Kafka cluster to regular GCE instances from Dataproc using our new IaaC setup). Dataproc is a managed cluster service that lets you spin up a working cluster in minutes based on your choice of image and size. Currently we are running Kafka 0.10.1.0 for Scala 2.11. Few hardships that we faced while setting up Kafka were the lack of resources on the latest version. The internet is full of amazing material for version 0.8.X for which most of the stuff is deprecated in 0.10.X, some of it was supported in 0.9.X with which we started off, but for the same reason that there is so much stuff on the old version we decided to go with the latest i.e. Kafka is a one time installation and once you start storing Gigabytes of data upgrading isn't a trivial task anymore.
Amount of datasets that we generate and store in S3, moving them ain't an overnight task, so we needed a plan for migration in phases. Once again our long time trusted tool fluentd proved a worthy choice to use. We used fluentd copy plugin to stream data into Kafka along with storing it in S3, keeping our current pipeline intact and started to roll out the new pipeline along with the old one with zero impact to the business ;). To avoid all our servers from talking to Kafka and to make a single secure connection between both Amazon and Google cloud, we transmit all data meant for Kafka to a fluentd server a.k.a Tron, to us. Tron, from there on it forwards data in small size/time based chunks as recommended by Kafka to achieve higher throughput with impression of low latency as it is transmitting in near real time.
Once we had our producer working for Kafka , it was time for a consumer to start pulling data and push it to GCS. With some research over at Github we found Secor from Pinterest to be a viable option for our use. Though it being a great piece of software, it wasn't mapping ideally to our design, for that purpose we had to submit few Pull requests to make the necessary changes to the secor project for our use and the greater good of the open source community. From updating the docs (PR268, PR271, PR277) on how to set it up to adding flexible upload directory structure with hourly support (PR275) and support for partitioned parser with no offset folder (PR279), also added flexible delimited file reader, writer option (PR291) for better control over file structure. Below diagram is our current ELT pipeline running in production.
Before we moved to using the data from Kafka, we kept it running as our secondary datasource imported in to Big Query to compare the data count. The data count seemed to be better coming from Kafka indicating that we were losing some data via our S3 based pipeline. As we started adding more and more datasets to Kafka we eventually hit a road bump due to memory issue causing server to fall out of the quorum, which was initially hard to identify with errors in the Tron server. The issue 97 was opened over to discuss on Github in Fluentd Kafka Plugin repository. That got drilled down to the plugin's limitation to counter it bound to the use of the gem ruby-kafka, a fix PR294 was contributed to resolve the issue from happening in future. The fix is now part of the fluent-plugin-kafka as well which will benefit many others. Happy to say that the patch works well in production :).
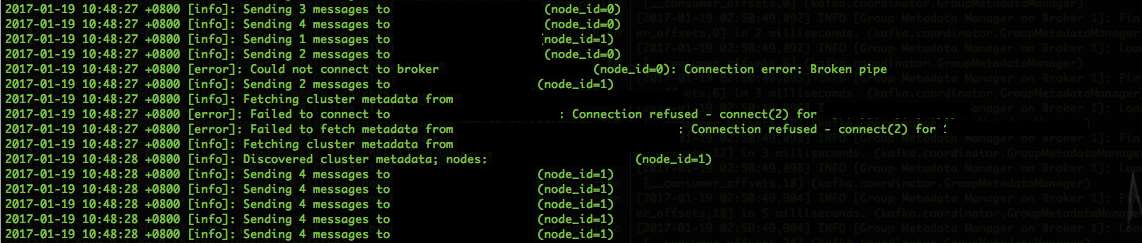
Few tips before I close this blog post, always have enough memory in Kafka server as it is very memory intensive and tends to shutdown gracefully every time it hits heap size limit without indicating anything in the logs. For monitoring your cluster use Kafka Manager, it does the job very well and also have KafkaT on server which saves you from running cumbersome builtin Kafka commands.
We had our Christmas and New Year in peace with our pipeline performing well over the holidays, and hope to spend more with the same consistency coming Chinese New Year. We are always looking to make our technology stack better and do necessary improvements to provide better performance. We like to take up challenges and solve them and in process learn as we grow.
Update 06072018
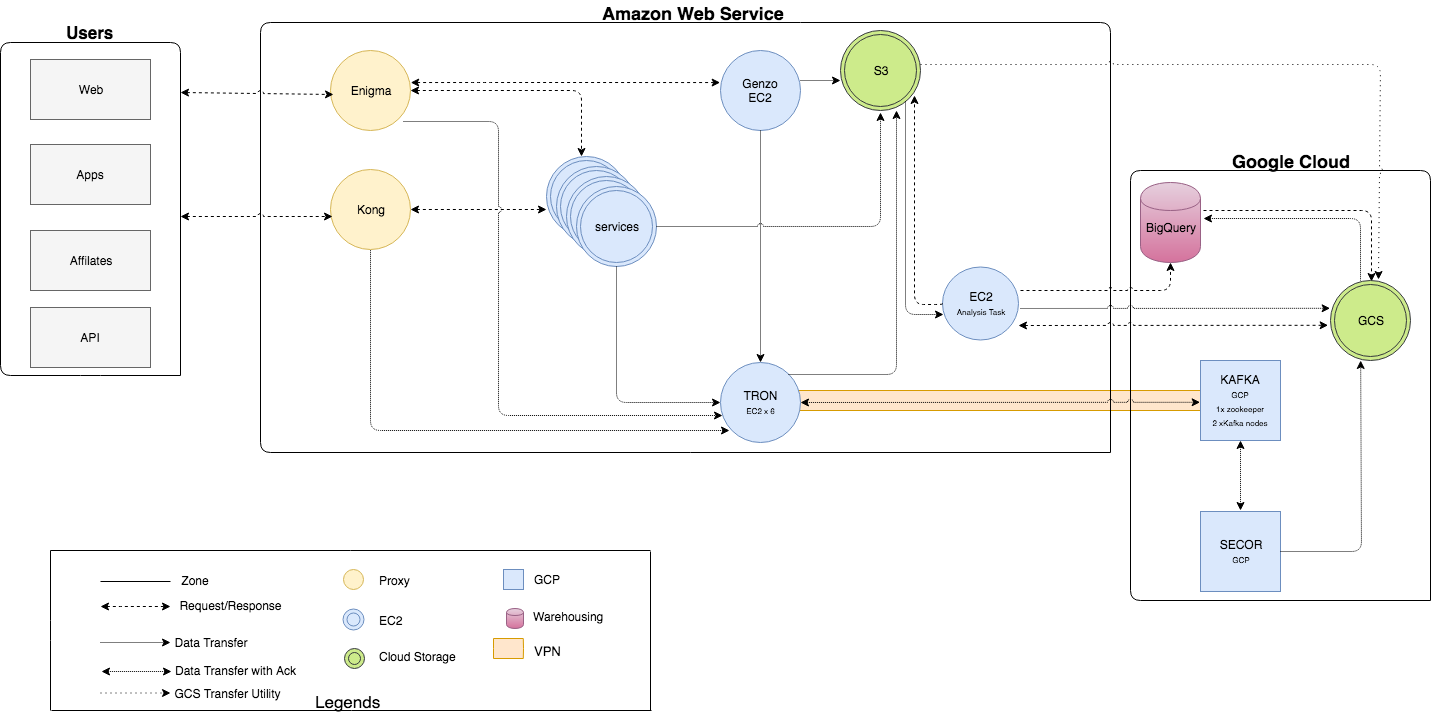
We have updated our batch pipeline which was running via our in-house AWS-GCS transfer utility to Google's GCS transfer utility and are using it for non-critical and time insensitive data. It has been performing well and we have managed to take the management and load of our engineers.
The detail diagram showing the whole design in action is in the below diagram.
View Comments