Images are one the most important factors when it comes to choosing which hotel to stay in. If a hotel's images don't look appealing, it is unlikely a customer is going to book it.
Making sure every hotel's images are as appealing as they can be is a challenging task, however. Wego has close to one million hotel properties and for each property we can have tens, sometimes hundreds and, in a few crazy instances, thousands of different images. To further complicate matters, we get our images from a variety of sources- our partners as well as 3rd party vendors. As a result, the same (or roughly the same hotel image) can be hosted multiple times with various image quality and image dimensions.
Showing repetitive images to customers is obviously bad UX. It also means increased costs for image hosting and increased server traffic. Getting rid of duplicating images is a process called deduplication and is something we have spent a lot of time perfecting. We do deduplication every time there is an image update, so it is important that the process is efficient, scalable and fast as we host close to 100 million images in total. Further, classification of images at scale enables us to intelligently group images and choose the best image to be the main hotel image.
In this post, we focus on a few of the technical challenges we had to figure out related to dealing with images:
- Speeding up image processing
- Leverage Google's Vision API for image tagging
- De-duplicate and image ranking.
Image processing
Historically, processing and reindexing of images has been a very slow process. In one particular instance it took over a month to process all images Wego had at the time. Waiting for all images to be processed wasn't fun. To avoid such huge waits we often resorted to processing the images for a particular geography only which clearly wasn't ideal either and it led to a number of iterations with the commercial people asking whether we can process this geography or that set of hotel properties. And sometimes multiple request would come at the same time, so we had to run multiple background jobs concurrently.
There are two ways to scale up processing of images
a) have a big enough server that can can handle even the worst case scenario which in our case was having to run multiple, big jobs
b) having a queue in front of background job servers.
Clearly, both approaches have significant downsides. The large server approach meant most of the time the server is under-utilised and Wego is paying for having a powerful server dedicated to it. With the queue approach, there would be delays whenever there are a lot of tasks in the queue which can be a problem with managing the expectations of the commercial team and outsiders whenever they come with a small image request that is urgent.
To deal with these and other issues, we decided to go with Serverless infrastructure which dynamically scales up or down depending on numbers of outstanding jobs. Both AWS and Google Cloud provide such a service.
AWS Lambda executes our image processing code only when needed and scales automatically, from a few requests per day to thousands per second. We are paying only for the computation time we consume - there is no extra charge when the code is not running.
AWS Lambda currently supports Node.js, Java, C# and Python. We have adopted an opensource serverless framework and then build/deploy different lambda jobs on top of that. We are able to run thousand of jobs per second.
The image processing lambda job will be invoked for each hotel and tasks will be run simultaneously. Some of the main functions of this task are the following:
- Query all images for each hotel from multiple partners;
- Remove low-quality images (based on image size) and remove duplicate images;
- Apply image ranking based on image size, partner's ranking and the tags that we've assigned to each image which will be mentioned in the next session;
- Ordering images based on rank and upload to our cloud storage.
Machine learning and image analysis
We used Google's Vision API to understand the content of the images at scale. Google's Vision API encapsulates powerful machine learning models in an easy to use REST API. The API quickly classifies images into thousands of categories like rooms, bedroom, tower_, etc, correctly recognising objects and features an image contains.
From sample data, we defined a list of good categories which we will give a high rank such as rooms, exterior design, landmark, etc. A few examples:
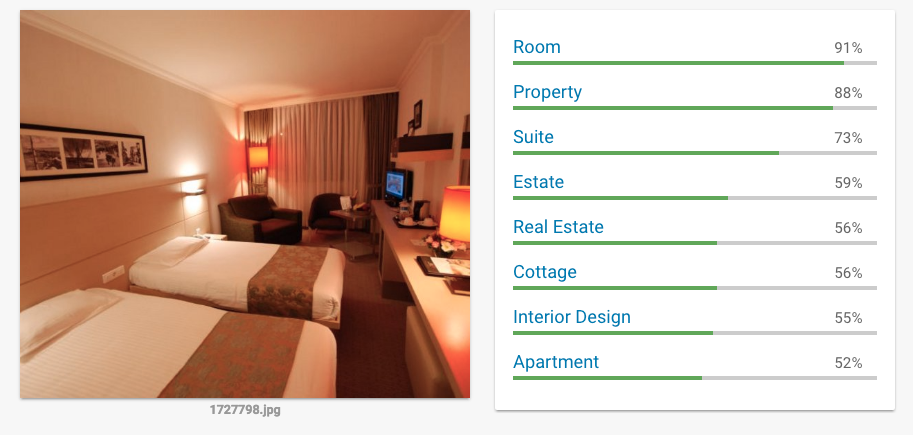
Some categories we simply did not care about and chose to ignore. Other categories such bathroom, face, toilet were de-prioritised as we didn't want such images to appear as our main hotel image.
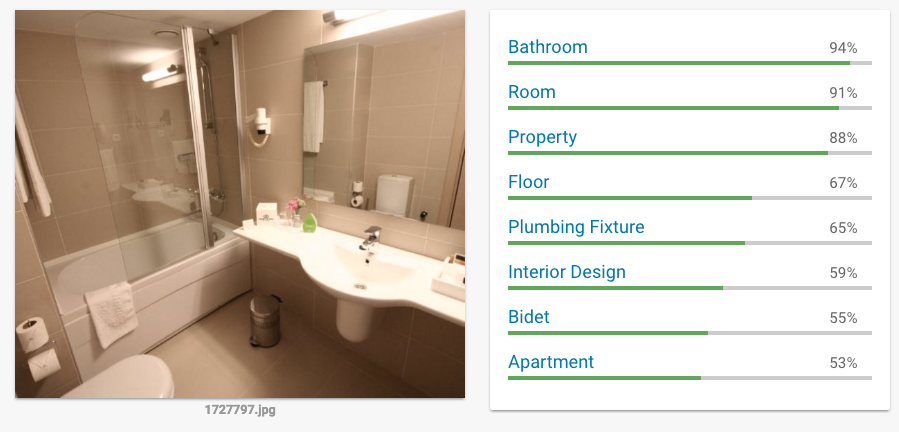
There were a few iterations until we came to a good set-up for categories but moving from one version to another was fairly straightforward. And while it took a bit of time until we couldn't find any more edge cases where the logic would fail, even with the first couple of iterations we saw an overall improvement over the status quo.
Image deduplication and ranking
We use [pHash](http://www.phash.org/, https://github.com/aaronm67/node-phash) to remove similar images. We played with different thresholds to ensure there were no similar images. Again, a bit of a trial and error until you find the right balance but overall a fairly straightforward process.
With the image's metadata from the Vision API, image sizes, partner's score, we came up with a basic weighted average scoring mechanism to estimate image's overall score which we then used for the ranking of images.
Image score = size_score * size_weighted + partner_score * partner_weighted + category_score * category_weighted
Summary
Using serverless technology really sped up our image processing while also saving on server costs. Applying widely available machine learning technologies allowed us to classify images which we then used to qualitatively improve the order in which we show a hotel's images to the user.
We'are still working on this to make it even better.
View Comments