Real-time CDC using PostgreSQL, Debezium and Redpanda
Scroll DownChange Data Capture (CDC) is a robust design pattern commonly employed to track any modifications in a database. It enables the comprehensive monitoring of both data and schema alterations. The recorded data can subsequently serve as a critical input for decision-making within the listening or processing application.
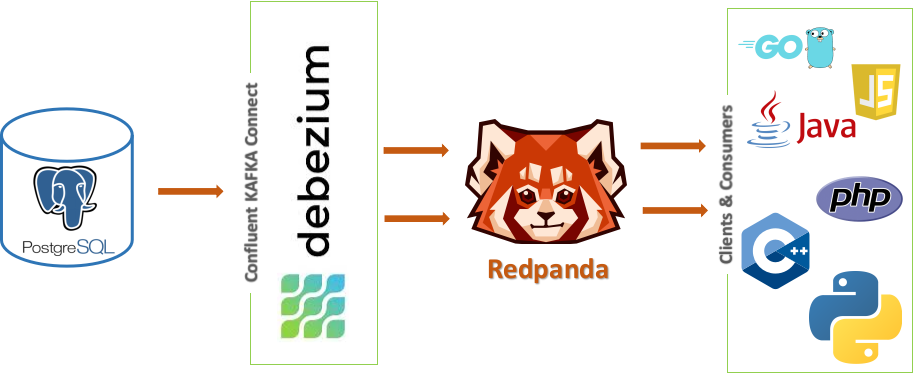
Several prominent database technologies offer built-in support for Change Data Capture (CDC), such as MySQL, PostgreSQL, SQL Server, Oracle, DB2, Cassandra, MongoDB, and others. In this context, the article highlights CDC within the MySQL database, which employs the "binlog" change log feature to capture real-time modifications. Subsequently, these changes are processed through Debezium, Kafka Connect and Redpanda facilitating downstream services and analytical dashboards with immediate access to the altered data.
Having a comprehensive grasp of CDC and leveraging CDC data within a real-time data pipeline system can significantly simplify operations in multiple ways.
For instance, CDC-based data processing minimizes the burden on the involved systems since it operates on an event-driven basis. This approach helps save time and effort when dealing with performance-related challenges.
Implementing Redpanda with Debezium and PostgreSQL for CDC
- Begin by setting up Redpanda, ensuring that you have the necessary binary or image that includes the essential components for streaming use cases.
- Make sure to integrate Debezium with Postgres to enable the capture of CDC data from the Postgres database. Configure the Debezium Postgres connector accordingly.
- Create a sample table in the Postgres database, such as "employees" where you can test the CDC functionality.
- Configure Kafka Connect to facilitate the transfer of the extracted CDC data to Redpanda.
Setup Docker Containers
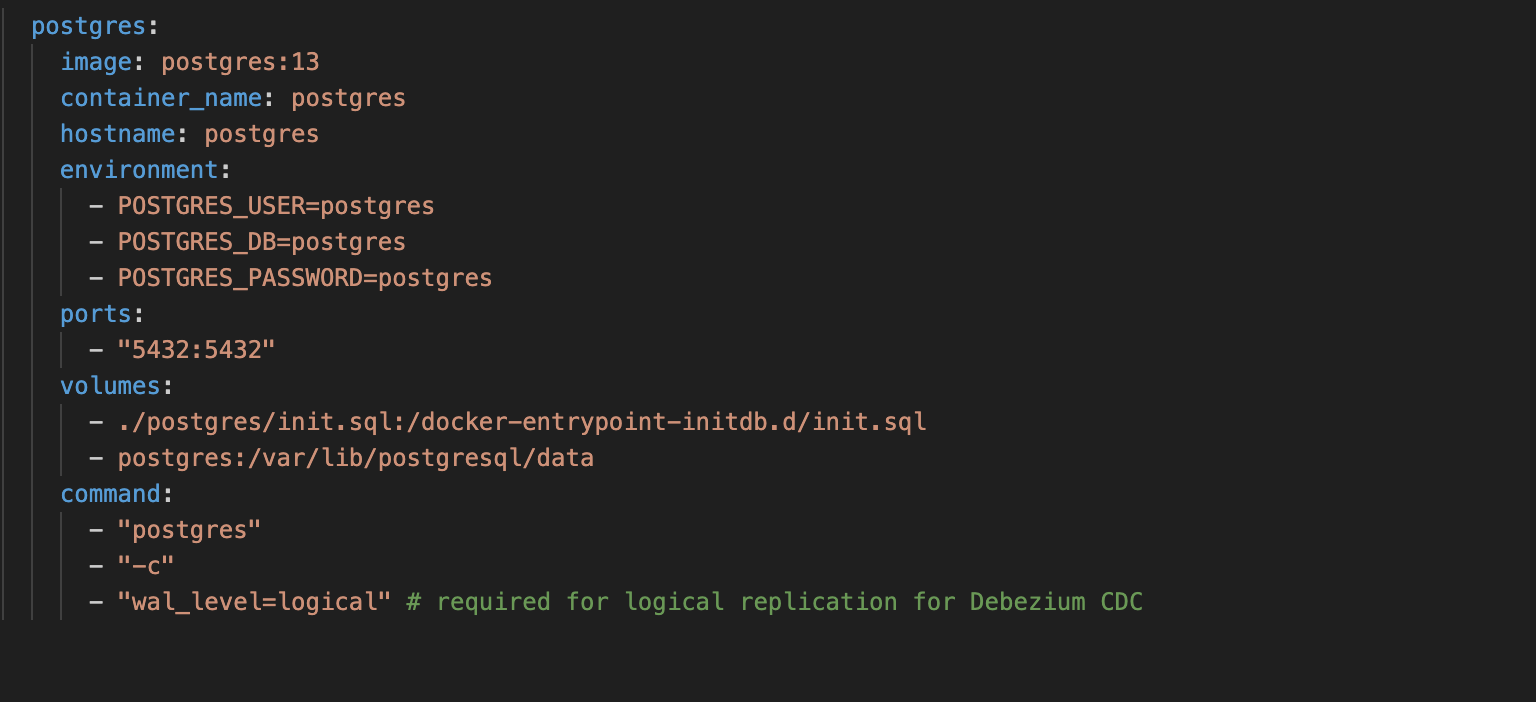
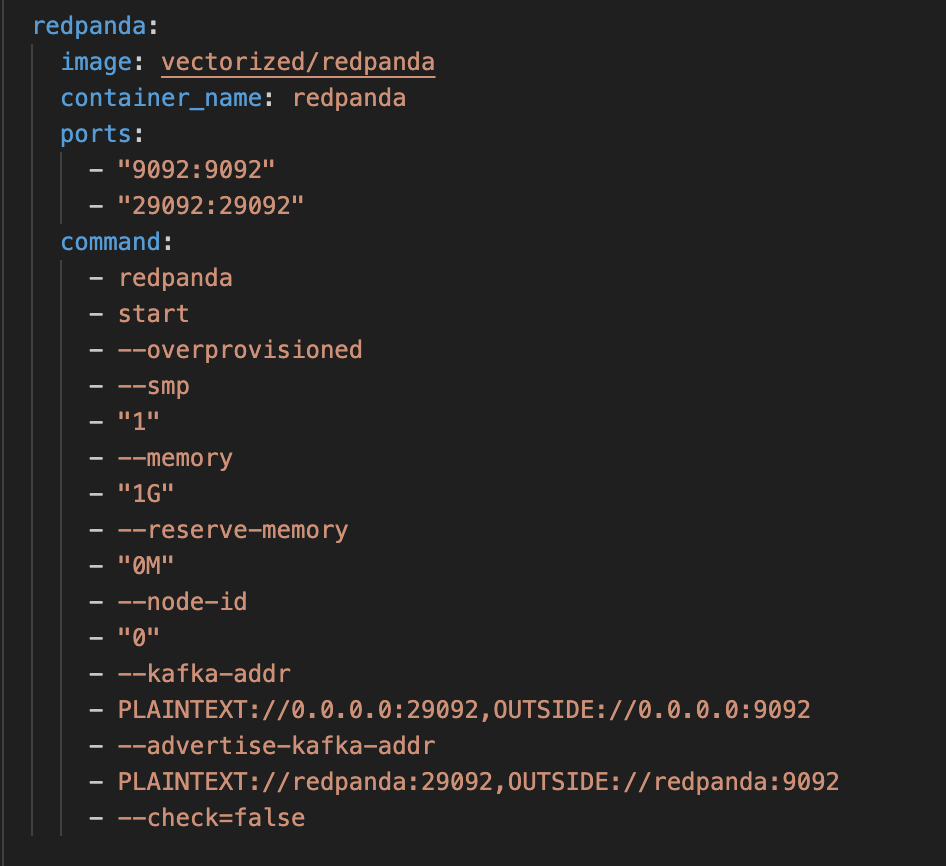
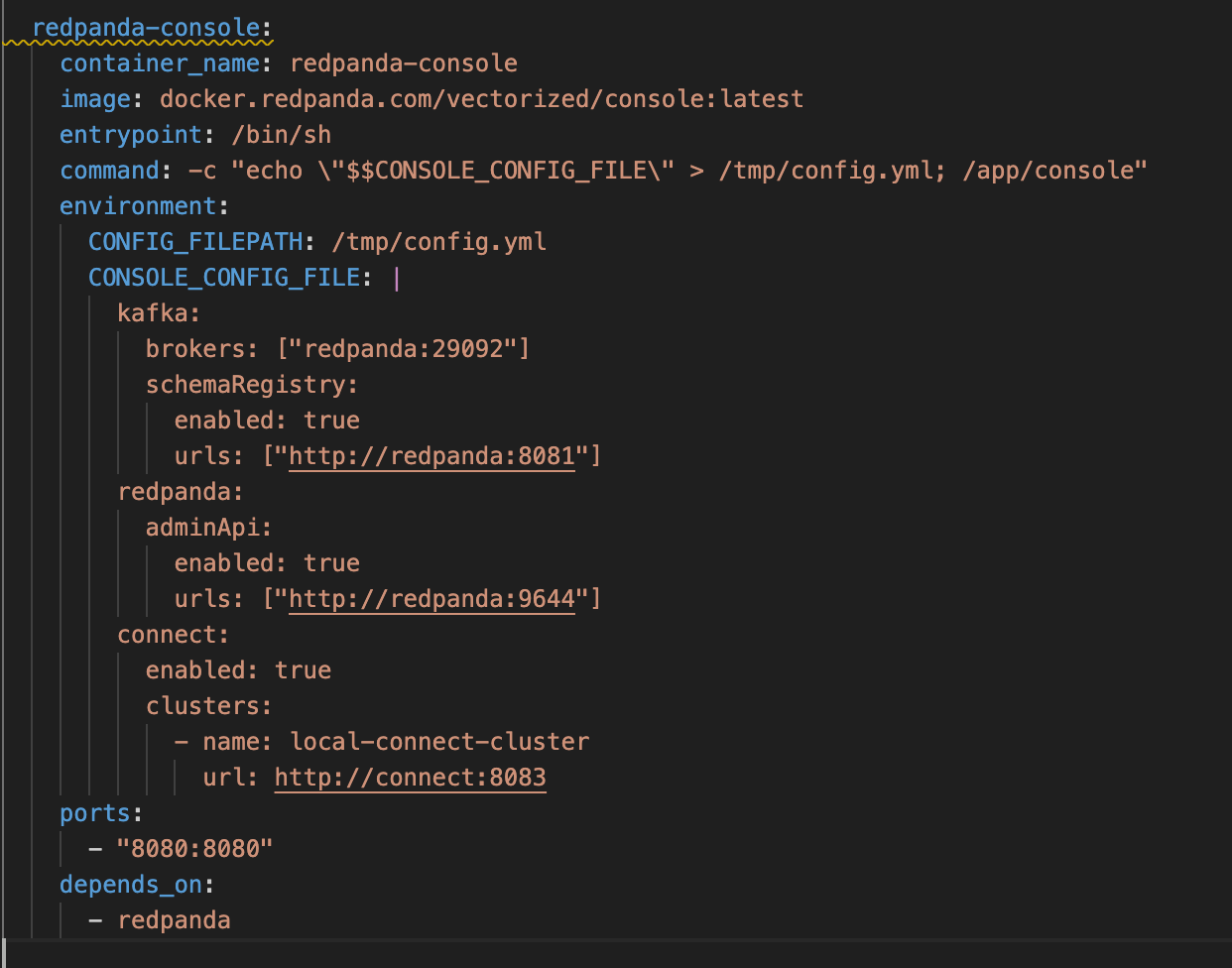
The Docker Compose file, docker-compose.yml, contains the relevant instructions for the list of images to be pulled and other settings that need to be configured for the container environment. A brief overview of this YML file is given below.
There are four services in the file:
- postgres - database
- redpanda - streaming data platform
- redpanda-console - the UI/dashboard for redpanda
- debezium - kafka Connect plug-in
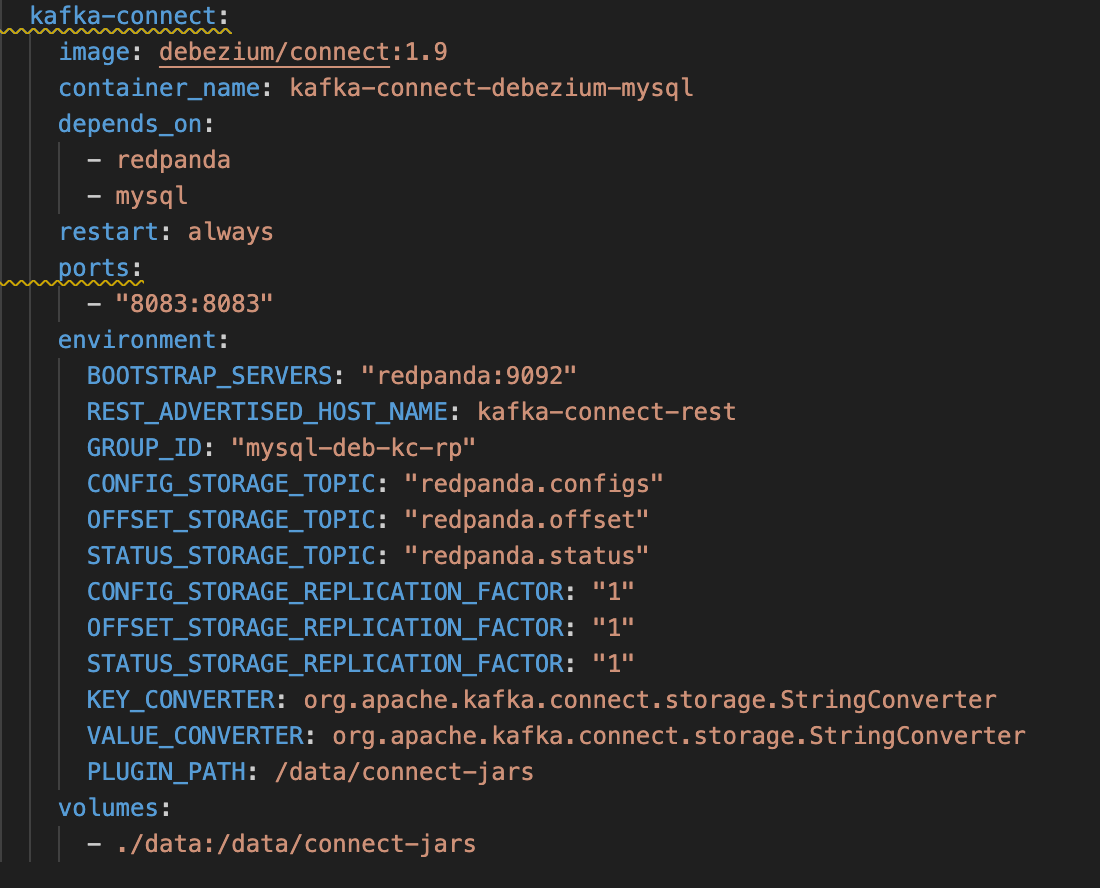
kafka-connect service definition uses Debezium's official Docker image to pull the Kafka Connect image. It listens on port 8083 for the incoming requests.
- The required metadata topics for the kafka-connect service is configured as part of standard environment variables, including the word STORAGE in it—for example,
CONFIG_STORAGE_TOPIC,OFFSET_STORAGE_TOPIC,STATUS_STORAGE_TOPIC. The main purpose of these environment variables is managing the internal operations of Kafka Connect, which are compacted topics that work seamlessly with Redpanda. - The
PLUGIN_PATHvariable points to the path from which to load Debezium's connector libraries. (/connectors/pg-src.json)
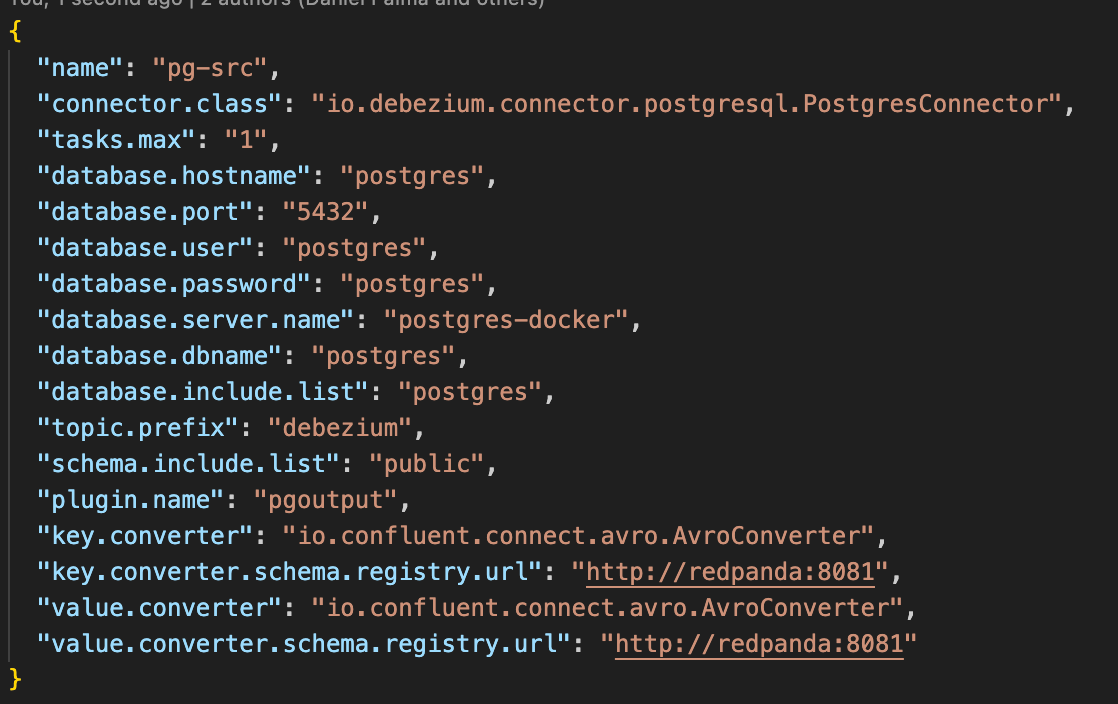
- The
KEY_CONVERTERand theVALUE_CONVERTER, are used to specify how you'll be formatting the data. We are going to use a simpleAvroConverter. There are also other types you could use, such as theStringConverter or JSONConverter; however, using theAvroConverterwould require that you serialize the data in your application code to be able to read it by casting it into JSON format. - Next, open a terminal and execute the following command to start setting up your machine.
docker-compose up -d
Open the Docker Desktop application on your machine, and click on the Container/Apps option in the left-side menu bar. You should be able to see that all four containers are up and running.
You can also execute the command docker ps to check the status of these containers.
Next, log in to the terminal of redpanda container by executing the command docker exec -it redpanda /bin/bash
Use the following commands to enable automatic topic-creation configuration, which is required to automatically create the topics in Redpanda, including Kafka Connect's metadata topics and the topic to receive CDC events data:
rpk cluster config set auto_create_topics_enabled true
rpk cluster config get auto_create_topics_enabled
The first command enables the configuration, and the second verifies if the configuration is enabled.
Open another terminal and log in to the kafka-connect container terminal by executing the command docker exec -it kafka-connect /bin/bash
Execute the following curl command to post the connector configuration to Kafka Connect:
curl -X PUT -H "Content-Type:application/json" localhost:8083/connectors/pg-src/config -d '@/connectors/pg-src.json'
Once the connector configuration is created, you can make a GET request to retrieve to see the connector name.
curl -X GET http://localhost:8083/connectors
Login to the redpanda UI/dashboard on localhost:8080 to see the topic created as well.
Testing CDC with PostgreSQL
Now that all the required topics are in place and the connector configuration is set up, open another terminal and log in to the postgres container with the following command:
docker exec -it postgres /bin/bash
select * from employees;
Next, execute the following command in the employees table to update the table's data and stream it to Debezium:
update employees set name='Alex Williams' where id= 1;
Finally, the data reaches the topic created earlier via Kafka Connect.
If you switch your terminal to the Redpanda container, you should see a new event received for the change made in the database table.
Conclusion
With the example project in this article, you have now experienced the power of real-time CDC processing with Debezium and PostgreSQL via Kafka Connect, and Redpanda. Changes in database tables are streamed through the data pipeline and reach the topic as they happen.
View Comments