Wego strives to provide the best user experience and results to its users. In order to do so, we gather best possible rates and fares and compliment them with the best available reviews to help our users make a decision to enjoy their travel.
TrustYou is a leader in providing reviews for travel industry and one of the big data travel review partners we work with closely, ensuring we have the latest data for our users. Being a featured partner on their website is an indication to how closely we work to bring the best to the travellers. TrustYou works with over 50,000 hotels worldwide providing us with useful reviews for our users.

As Wego gets millions of users and thousands of unique searches everyday, querying reviews and caching isn't a very feasible solution and not one recommended by TrustYou either for their API users with such high demand. The solution they provide is Meta-Review Dump. It is a data dump published every week with the latest reviews for all the hotels in their database.
Meta-Review dump is a huge dataset considering it provides reviews for over 50,000 hotels. The way the data set is divided is by hexadecimal numbering in an AWS S3 bucket. So there are 0-F folders with each folder further having 0-F datasets, making the total of 256 datasets to process. Each dataset in uncompressed form to process is over 3.5GB, which puts total data to be processed close to a Terabyte.
Our initial design use to take us around or over 2 weeks to process all the data, based on AWS SDK and Ruby, a language most of the developers are familiar with at Wego, so using the Ruby sdk seemed to be the obvious solution. The sdk was slow in the download process as it would download the file to memory which was then for the developer to write it to disk, before uncompressing it for processing. This limited us in ability to process files at a faster pace, as it was to be done once till we felt a necessity to update the reviews, it seemed acceptable to take this route. This logic had one major flaw, that if the process for some reason stopped in the middle, the processing would initiate from the beginning. Though we didn't face the problem due to sound coding practices and testing that we follow. None the less, it was a limitation at our end.
Recently TrustYou updated their reviews, categorising them by Traveller types i.e. Family, Solo, Couples and Business. This information is very valuable from a traveller's point of view, which meant our users expected this from us. This also meant the amount of data to be processed also increased approx. 4x times. This called for review of our logic on how to process the Meta-Review dump.
The first thing to do was to parallelise the process of download, which would free us from downloading a single file every time before processing it. For that we replaced AWS SDK with S3tools, and used Ruby fork and detach support from Process module to create a small background job service we can poll, that would download a complete folder containing all 0-F datasets, which we can then process locally before moving to the next folder. This freed us from worrying about our program crashing in between for us to start over again as we already had the data to process downloaded and we could download any dataset folder as need be.
Great, we had our downloads in parallel, but the downloaded data is compressed to 90%, which meant improvement on only 10% of the task was accomplished with this change, then came the next bottleneck, the processing of JSON objects in each file. To put it in to perspective the size of each JSON object, In MongoDB each document has an upper limit of 16MB and in MySQL sense the text column type max outs at 16MB and each Meta-Review JSON object could consist of multiple key value pair over 32MB. So traversing over each object and extracting relevant information, meant lot of in memory processing and writing millions of records to the DB, another bottle neck only waiting to hit us head-on.
As each object consisted of multiple parts i.e. Good to Knows, Hotel Reviews, Meta-Reviews, Summary etc. There was an obvious opportunity to asynchronously process the object and extract all values as it was already in memory. Some inspiration was taken from the Actor Model to design the process to handle objects. Each object was considered the supervisor and all subsequent objects from it as its workers. Every worker would work in their own threads and return extracted information to the supervisor, avoiding any deadlock or starvation among the threads. Some worker objects have further nested data which are processed using the same async model where each worker object becomes supervisor to its workers. This approach made sure that each object's processing time would be approximately maximum time it took to process any part of that object.
In order to maximise the speed of writing to the DB, we used Active Record Import to write and update records in bulk. This assured that we only update reviews that have already been imported in previous runs and create new ones as they are added by TrustYou.
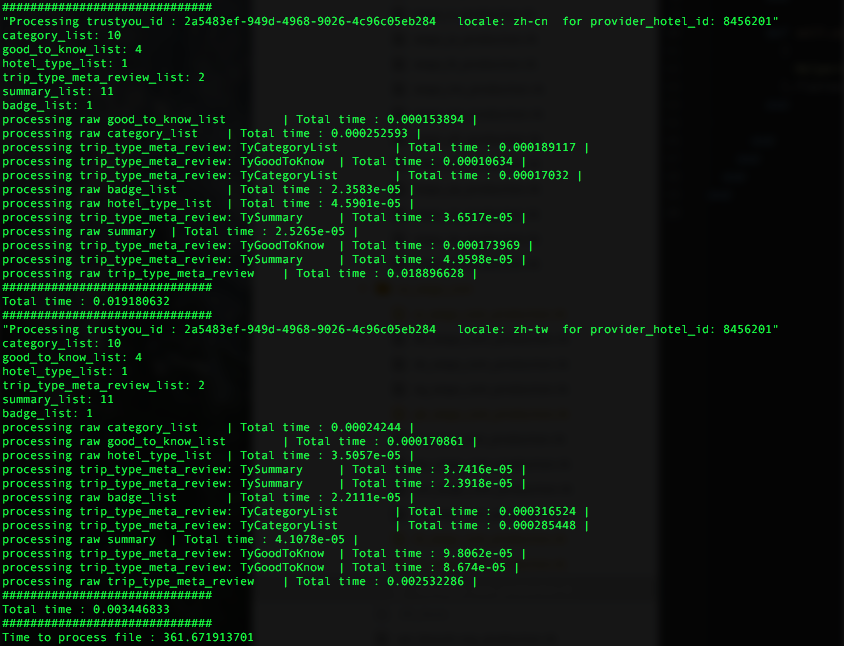
As there are millions of objects to process and this whole parallelising of task saved us not just hours or days but weeks of processing. Currently we are able to process all of TrustYou data in little over 18 hours compared to previously taking weeks, while we process all folders in sequence, if need arises for us to process them in parallel, all can be processed in under 3 hours as entire task is designed to run independently on each folder containing datasets.
View Comments