Wego supports around two dozen languages and has localised websites in over 50 countries.
Over the years, adding configurations for each new domain to our repository, bloated it, and created a huge redundancy of location blocks in the files which remained, even after they had expired.
At times even by dividing into separate conf files, and adding them to the main config using the nginx include directive, made it hard to navigate and remove a location block for a specific domain, without affecting others that still might be using them.
Hence we assigned the name Enigma to our replacement proxy server.
The main objectives for this new proxy server were:
-
Update the
nginxto the latest version. -
Setup
nginxstatus monitoring and integrate withNew Relic. -
Setup
nginxlog upload toS3 -
Import log data to
BigQuery -
And most importantly, automate the
nginxconfiguration creation and deployment forEnigma
Why we needed Enigma, a web proxy

The user request flow for Wego is directed through many servers before arriving at the application for processing.
Users--> Domain (DNS)--> CDN (Edgecast) --> Proxy (Enigma) --> Application server
The advantages of this user request flow approach, is that there is a centralized point for incoming traffic from multiple domains, which tunnels all traffic through the proxy (Enigma), allowing us to easily monitor the traffic coming to our application.
The reason we decided to stick with nginx for our new proxy was due to our team's previous management experience.
nginx has a proven track record in the www space for being stable and popular (nginx served or proxied 23.94% busiest sites in November 2015), which was another good reason for our selection.
How we set it up
Our old proxy server Dairi was running nginx 1.4.6, the latest available upgraded version was 1.9.5, giving us status monitoring plugin support and new relic integration.
We use chef to setup all our servers, so upgrading the server required an upgrade of the cookbook, which turned out to be a bottleneck, as Nginx Cookbook doesn't support installation of versions beyond 1.4.6 by default.
To overcome these limitations, required us to override a handful of cookbook variables, to cook what was required.
(as of this blog post the maxmind geoip dataset checksum needs to be manually calculated and overridden to be able to use the geoip module of nginx)
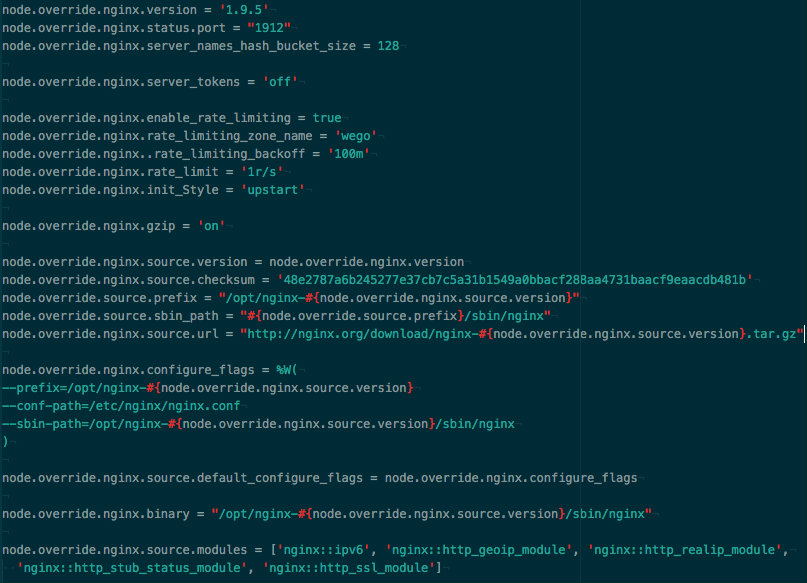
As status plugin is not part of nginx 1.4.6, we needed to setup a custom version for NewRelic status plugin recipe, to get it up and running as it's not supported by the cookbook.
(Since writing this post we have switched to OpenResty which is a full fledge Nginx core with LUAJIT support and has an up to date Chef Cookbook with lastest nginx version, this has resulted in less hacking of our Chef recipes, we setup GeoIP plugin ourself and configure it for install by the recipe along nginx)
We receive millions of requests per day at Wego. To provide optimum service and a better user experience, the log data provides us with the most valuable datasource for gaining insight into our performance, and also alerts us to any issues.
We write all requests to a single server-access.log making it easier to process the data from a single file. fluentd is the defacto tool that we use to upload data to our S3 buckets regularly. Once the data is in the cloud , we import into BigQuery using our in house written service S3toBQ and connect it to ChartIO to give us insights into the request data performance, which might not be otherwise visible from raw logged data alone.
logs → fluentd → BigQuery → Chartio
Turing Overview

Anything that could break our proxy server Enigma couldn't be named better than Turing.
As with the original Turing machine, it also took some time before we saw the results we needed, but in the end it was all worth the wait, and we won the war against the blot-war(e) in our configurations.
The goal was to have a templating engine that would be used to generate configuration files for nginx which can be used for adding domains to Enigma, and have a failsafe deployment of those configurations which we can roll-back should we need to.
Setting up a templating engine was quite straightforward using ERB, but we needed support for Rails like partials, which apparently aren't built into any of the template gems.
It was still comparatively easier to implement the functionality in ERB than slim and haml. This gave us the flexibility to use the same location block template for a variety of directives that we needed to declare, just by adding them in a list of array per file for each domain, and to reuse them across a domain as required.
This approach provided us with many benefits that have helped in the maintenance and deployment of new conf files , such as:
-
Migrating old
conffiles, but generate using templates rather than hard coding a file per domain. -
Removal of redundant location matching blocks added over time. Previously, to upgrade a
conffile, exact matching location blocks were defined over present location blocks to avoid conflicts of presence in subconffiles part of the mainconf. For example, we had block matching 2 or more character locale defined in the sameconffiles.
** ~* ^/..(-..)?/hotels/api**
** ~* ^/..(-..(.)?)?/hotels/api**
-
Able to use repeated location blocks which were defined in multiple files, mainly locale specific blocks. As an example,
esandes-419had similarspanishlocations, which are now just defined in aYAMLfile, and the same block of code generates theconffile. (nginx doesn’t permit multiple definition of identical location blocks) -
Configurations are now easily searchable as all locations are in a single generated file compared to previous
conffiles, which consisted of multiple files linked together. It makes it easier to debug in both code and final output.
Deployment Strategy
Each of our deployments occur under a dev user which has limited permissions in order to avoid any faux pas. To avoid these situations we have nginx under the sudo user to restrict who can deploy changes to the server, as the single entry point to all our traffic.
For this purpose we cooked sudo permission to operate nginx for our admin user into Enigma.
Capistrano is the default deployment tool that's used at Wego, and we use it to deploy not only for different users but different configurations to different servers from Turing.
Your best friend for ensuring generated conf files are valid is:
/usr/sbin/nginx -t
We have integrated this into our capistrano deployment recipe. The following output indicates if your configuration is valid and the server up and running.
nginx: the configuration file /etc/nginx/nginx.conf syntax is ok
nginx: configuration file /etc/nginx/nginx.conf test is successful
This is only to test if conf files are valid for nginx to be operational. To ensure they're sound for our application to work, testing is the only approach. Currently we use a server in a staging environment, with production conf deployed. We call it production_staging.
This helps us to ensure no downtime due to configuration errors in our conf files.
Dashboard & Monitoring
As they say there are no better tools than Command Line tools - the swiss army knife for every developer.
It's our first line of monitoring as a developer to quickly tail and grep for any error that might occur in our Enigma, or to be made aware if Turing has finally cracked it.
tail -f /var/log/nginx/server-access.log | grep -E 'server_name\": \"wego.com\"' | grep -E '\"status\": 404'
tail -f /var/log/nginx-nr-agent.log
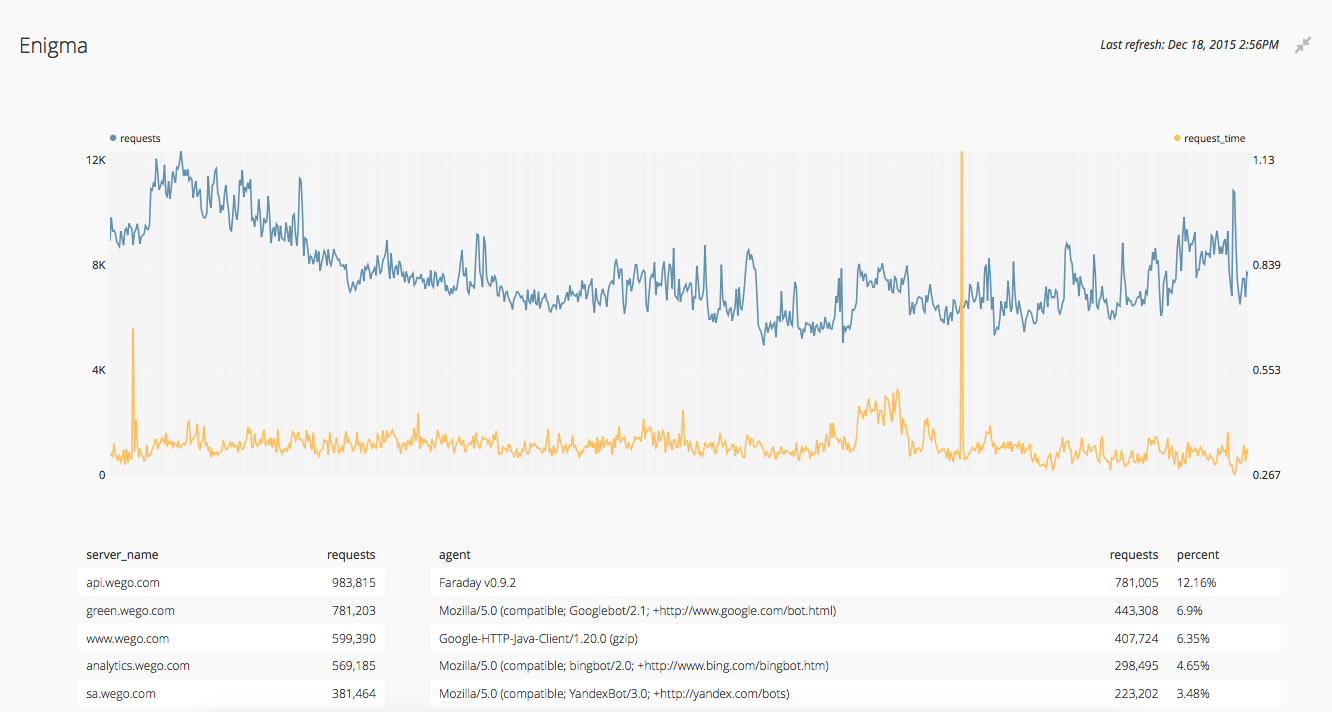
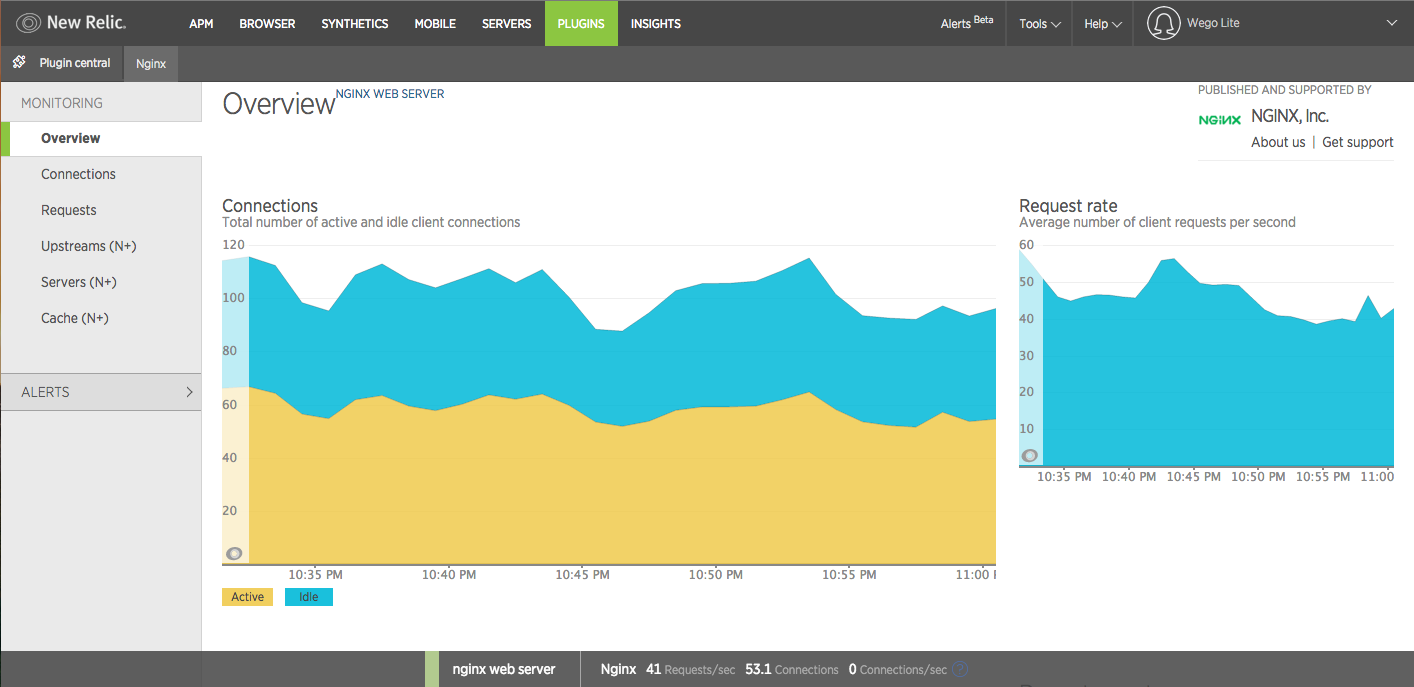
cli tools are great, but based on the amount of data it is not easy to find issues which would be impossible to notice without visuals. This is where we use ChartIO and NewRelic, generating user friendly graphs and charts to provide insights across teams and help them better understand the impact each request makes.
ChartIO
New Relic
View Comments