Cross-region Redis replication
Scroll DownAt Wego, we are moving towards a multi-region infrastructure to reduce latency for end-users as well as improve resiliency for our critical systems. For multi-region infrastructure to work, each regional service should access its own regional data stores (S3, ElastiCache etc.). This means applications that are uploading data to a single data store, now have to upload data to multiple regional data stores. As the second in the series on multi-region infrastructure at Wego, this article covers the design and implementation of our home-grown cross-region data replication, as well as highlighting the interesting challenges and learnings we encountered along the way.
Requirements
We are using Redis to speed up application performance since accessing memory is faster than accessing disks. The source of all Redis data comes from the microservices in the Singapore region. Basically, they fetch data from databases and upload them at regular intervals. Previously, we only have one region so the data updates were straightforward - the microservices just need to upload data to a single Redis instance. In light of a multi-region infrastructure, data updates will have to be propagated to multiple regional Redis instances.
We also decided to forgo strong consistency as a requirement. It is acceptable if Singapore and Mumbai have slightly different hotels data as long as the difference does not hurt the user experience. Hence, we opt for the eventual consistency model since differences between regional non-critical data can be tolerated for a short period of time. Eventually, data will be synchronized and will be the same across regions. This non-requirement simplifies the replication system greatly.
Approaches
The naive approach is to iterate over the list of regional Redis instances and execute Redis commands to upload data for each instance. This is not a favourable approach because the source region and the destination region will be tightly coupled with each other, violating the separation of concerns design principle. We also have to handle retries and failures on the application layer. What if a piece of data is uploaded successfully to a Redis instance in region A but failed to upload in region B? Such error handling will greatly complicate the application code.
Moreover, we have to resort to atomic transactions to make sure each data update succeeds for all regions before proceeding to the next update. This will also greatly slow down the overall data throughput in the event that a regional Redis is under heavy load and is unable to process commands as fast as the other regional Redis.
We also evaluated third-party solutions such as RedisLabs. It provides both multi-master and master-slave replication features. However, the pricing is prohibitive. The other solution is to use open-source Redis for its master-slave replication feature. The master and slave will be placed in different regions, making cross-region replication possible. This is a cheaper alternative but it would be an operational burden to set up and maintain.
We decided to hand roll our own cross-region replication system by building a message bus with SNS, SQS, and Lambda. To that end, our solution combines the best of two worlds - cheap and easy to operate.
Message Bus Architecture for Cross-region Replication
Affectionately named as Regis, a portmanteau of region and Redis, the message bus architecture consists of a pub/sub system, message queues and processing units working in concert to update the regional Redis instances reliably.
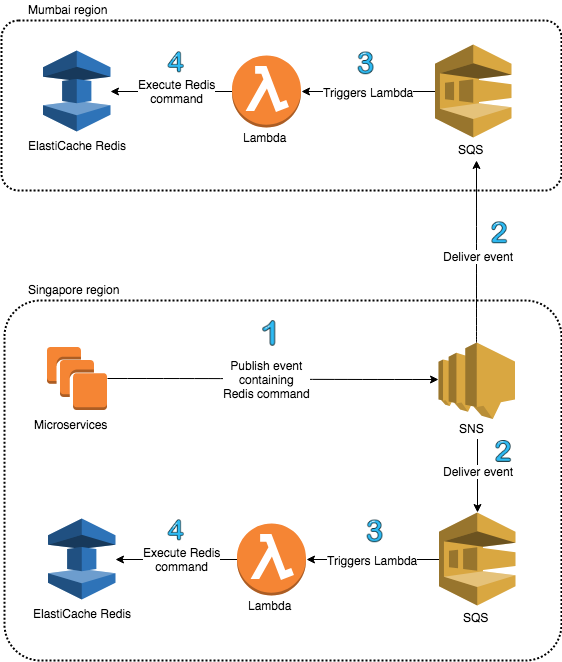
This diagram shows the unidirectional data flow through Regis:
- Instead of updating Redis directly, microservices publish messages containing Redis commands to an SNS topic
- SNS topic will deliver messages to the regional SQS queues
- Presence of messages in SQS queues will trigger Lambda functions
- Lambda functions process the message and update the regional Redis
Component Responsibilities
Pub/Sub system
For Regis to work, we need to have a component that can deliver messages to multiple regions at the same time. This is where SNS comes in. As it is a fully managed pub/sub messaging service, we use SNS to coordinate the delivery of messages from the microservices to subscribing regional queues.
Since the pub/sub system provides an abstraction layer over the regions, the microservices are not aware of the regions that they are supposed to update for. Messages are published to the SNS topic which is the only component that is aware of the regions. This allows a loosely-coupled design where adding or removing regions only involves changes to the SNS topic.
Message queues
Given that the SNS topic can also deliver messages to Lambda functions, the astute reader may wonder if the message queues are necessary at all. The answer is that they are not just necessary but absolutely critical to the reliability of the replication system. Even though SNS topic can send messages containing Redis commands directly to regional Lambda functions, those functions may fail to process the Redis commands due to invalid input or a Redis instance outage.
In the event of message processing failure, it’s a good idea to retry the messages. This is where the message queue comes in. They store the messages so that they can be retried after some time. Messages that are retried for too many times will be moved to a dead-letter queue, which can be used for debugging purposes. To that end, we use SQS standard queues for both the message queue and the dead-letter queue.
Processing units
The role of processing units in Regis is simple. They consume the messages from the regional SQS queue and execute the commands against the regional Redis. Since the whole processing unit can be implemented with a few functions, using EC2 instances is an overkill and can be cost prohibitive. Hence, we decided to use Lambda functions for this task.
If you treat a Lambda function as a thread, the processing units can be seen as an infinite pool of threads that can scale up and down in response to the workload. Simply saying, you only pay for what you compute. As with any managed AWS service, Lambda functions come with autoscaling and monitoring out of the box, which makes it easy to operate.
Design Rationale and Implications
SQS is a highly scalable and reliable AWS service, yet one of the implications for choosing SQS standard queue is that it doesn’t enforce FIFO message ordering. Doing so would mean if one message was being retried, all other messages would have to wait for that message to succeed. In the meantime, millions of messages might be delayed.
For this reason, the Lambda functions must be able to handle messages arriving out of order. However, reordering them is difficult. You could hold messages until any late ones have arrived, but how would you know how long to wait? If you waited 1 minute, the message might arrive 61 seconds late. It is best to write code that does not depend on perfectly ordered messages than try to reorder them.
Still, if the microservices update the same piece of data frequently over a short period of time, using SQS standard queue could lead to that piece of data being updated in a wrong order. In that case, we have to deal with the challenges of reordering messages. Fortunately, our data update pattern exhibits spatial locality, as we are updating different pieces of data in a sequence.
SQS standard queue also does not guarantee exactly-once delivery, hence the onus is on us to make sure our Redis operations are idempotent. By using a subset of Redis commands like GET, SET, HGET, HSET which can be erroneously executed multiple times with the same outcome, we are able to relax our requirements on exactly-once delivery.
Of course, if our data updates exhibit temporal locality and rely on non-idempotent Redis operations, then SQS standard queue is not a good fit. SQS FIFO queues would be a better fit since it enforces FIFO message ordering as well as exactly-once delivery. The deal breaker would be that it is not available in the Asia-Pacific regions. Hence, the solution is to avoid complexity in the first place by sacrificing 5% of the requirements to get 90% of the work done. By relaxing our requirements on perfect message ordering and exactly-once delivery, we can avoid a very large amount of design complexity and reach our goal of cross-region replication with a lot less effort.
Operations
As Regis is composed of managed AWS services, there is little to no operational burden. Each component of the message bus is infinitely scalable in response to the workload.
For the Lambda functions, there are times when they take several seconds to complete, but that is an anomaly since it can be a result of cold starts when spinning up fresh containers to run the Lambda functions. We are also relying on an eventual consistency model so it is fine if there’s a bit of consistency skew.
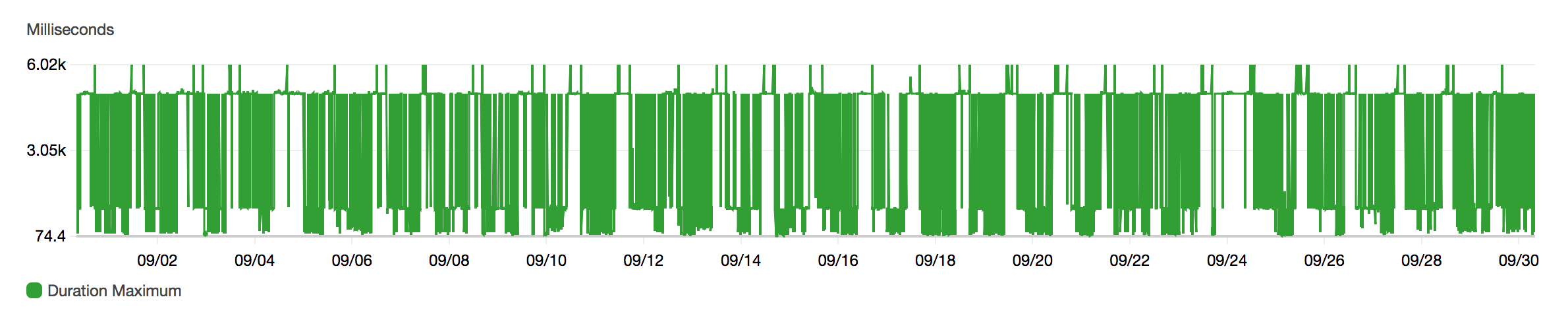
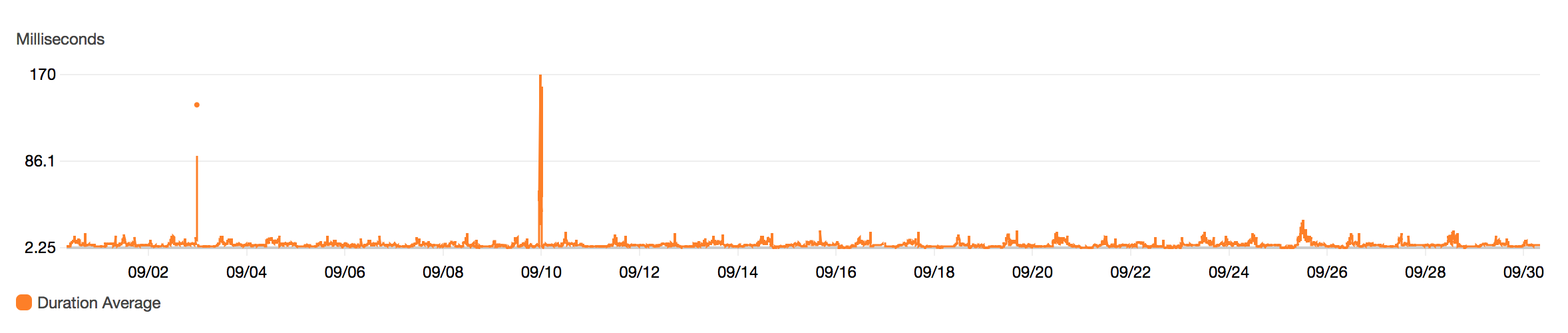
As seen from the average duration graph, the average processing time is around 6ms for the past month. There are brief spikes up to 170ms but overall the average duration remains consistent.
In addition, our microservices are hosted on EC2, so the time taken for the messages to flow through the message bus is greatly reduced since the data is transferred through Amazon’s private network, not through the Internet. For intra-region data transfer, a message would take around 50ms to travel from the data source to the Lambda function. For other regions, we have to take the extra inter-region latency into account. For example, the data transfer from the SNS service in Singapore to the SQS standard queue in Mumbai would add around 70ms to the overall latency.
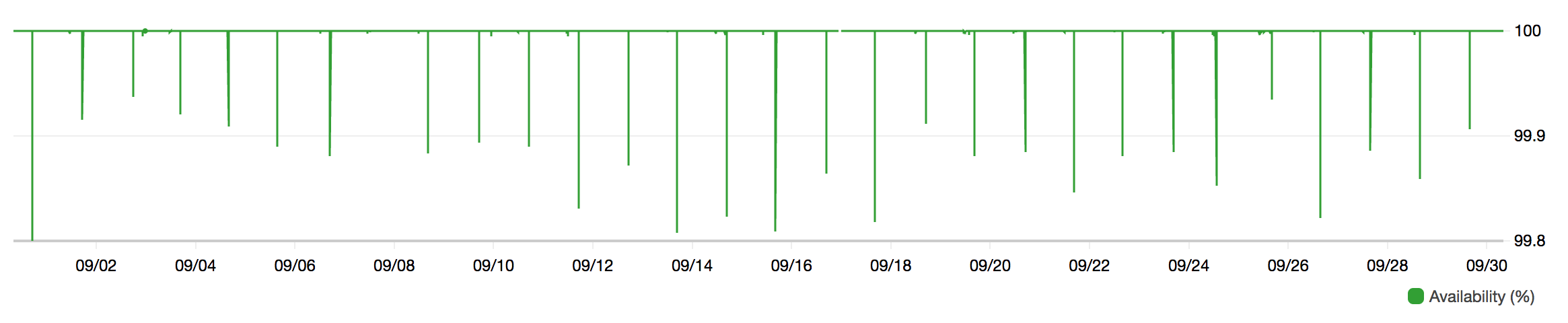
There is also 100% availability ever since we launched Regis. In other words, we haven’t received alerts since then. Moreover, we configured our Lambda function to integrate with Sentry for exception tracking. Erroneous messages are stored in the dead-letter queue for up to four days, this provides us enough time for debugging purposes.
Future Optimization
The maximum payload size of SNS and SQS messages is 256KB. The size of a typical Redis command sent by our microservices is around 200 bytes. Right now for each payload, we are sending a Redis command. In order to increase throughput and reduce cost, we can send multiple Redis commands per payload.
This will increase latency by a bit, but the SNS and SQS operating costs will decrease since we can pack more data per payload. In addition, the Lambda functions will process many more Redis commands per invocation, leading to a reduced number of Lambda invocations. The number of cold starts will also be reduced, improving the overall latency.
Conclusion
In this article, we have talked about the implementation and the design rationale for Regis. It is a critical system that we built to replicate Redis data across regions. This allows our users to retrieve the latest flights and hotels data from the region closest to them, ensuring a much more responsive user experience. We look forward to building more systems to support our multi-region efforts. If you are excited about building large-scale distributed systems, reach out to us, we’re hiring!
For other articles in the multi-region infrastructure series, please check out part 3 and part 4.
View Comments