Multi-region Traffic Engineering
Scroll DownWhen it comes to site reliability, traffic engineering is often an underlooked area. In most cases, it is not particularly interesting since the traffic flows in a predictable manner - from the CDN to the load balancers and then to the application servers. For a multi-region infrastructure, however, it plays a much more important role. After all, running multi-regional services would not be possible without a robust mechanism to route traffic to each region. As the last in the series on multi-region infrastructure at Wego, this article takes a look at traffic engineering in the context of multiple regions, by focusing on traffic management and automatic cross-region failover.
Traffic Management with CloudFront and Route 53
As all of our services are running in AWS, we are using CloudFront for traffic segregation and Route 53 for traffic routing.
Segregating traffic with CloudFront
Whenever the user makes a search on Wego, the client will send a search request to the nearest CloudFront edge location in terms of latency. Based on the specifications in our distribution, it forwards the request to an applicable origin server.
At this point, two things can happen:
- The request will always be statically forwarded to the same origin server.
- The request will be forwarded dynamically to origin servers in multiple regions via Route 53.
Simply put, the first Cloudfront behavior forwards traffic to single-region services, the second behavior forwards traffic to services running in multiple regions. To date, only a small subset of our services are multi-regional. Most of our traffic still flows directly to a single region. Hence, it is crucial that our CloudFront distribution contains behaviors to segregate multi-region traffic from single-region traffic.
Assuming the request URL path contains /metasearch/flights, the CloudFront distribution will execute the first behavior that matches the path pattern. In this case, the behavior will forward the request to the metasearch flights service running in multiple regions.
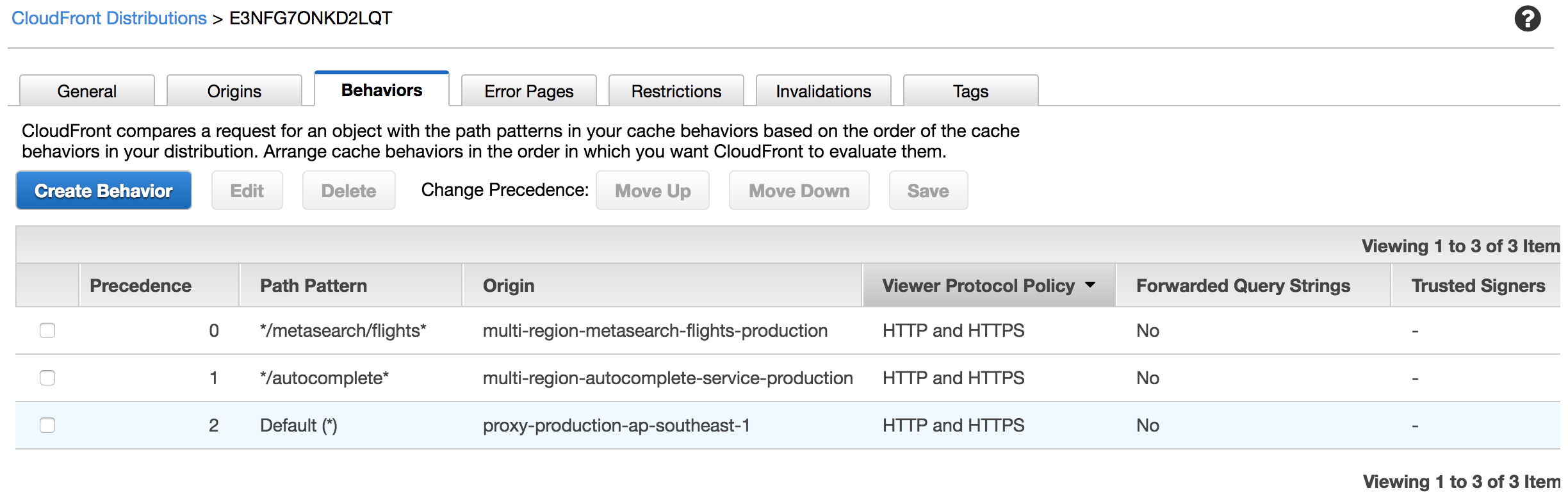
Since the CloudFront distribution job is to merely forward requests to the applicable origin, we shift the multi-region routing responsibility to Route 53 by configuring that origin to accept a domain name.
Routing traffic with Route 53
Route 53 is not just a DNS service, it also provides mechanisms to route traffic to multiple regions based on latency or geolocation. Such mechanisms are known as routing policies. When it comes to multi-region routing, we need to have a way to route traffic to different regions based on latency, as well as smooth rollout and rollback procedures when launching the multi-region project.
To that end, we require two routing policies - weighted policy and latency policy.
The weighted routing policy allows us to decide which weights to assign for single-region and multi-region traffic. For example, we would like to test the multi-region infrastructure by assigning 10% of traffic to latency routing, and 90% of traffic to the usual endpoint in a single region. This will enable us to gradually rollout our multi-region project. As is the case with any rollout process, it can go the other way around. The weighted routing mechanism also allows us to rollback quickly in case something goes wrong by assigning the appropriate weights.
Up to this point, we have talked about mechanisms for segregating single-region traffic from multi-region traffic and assigning weights to each of them for a smooth rollout and rollback process. This is done in preparation for latency routing, which is what makes multi-region traffic possible. As its name implies, it routes traffic to the region with the lowest latency. We could have used the geolocation routing policy but it does not guarantee the best outcome in terms of latency since the network between the user and the geographically closest AWS region could be slow.
As it is challenging to create multiple routing policies for the same domain name, we can use Route 53 Traffic Flow to create a traffic policy. You can think of traffic policy as a combination of routing policies. Traffic Flow provides us with a visual editor so we can create complex trees of policies with ease and visualize the relationships between them.
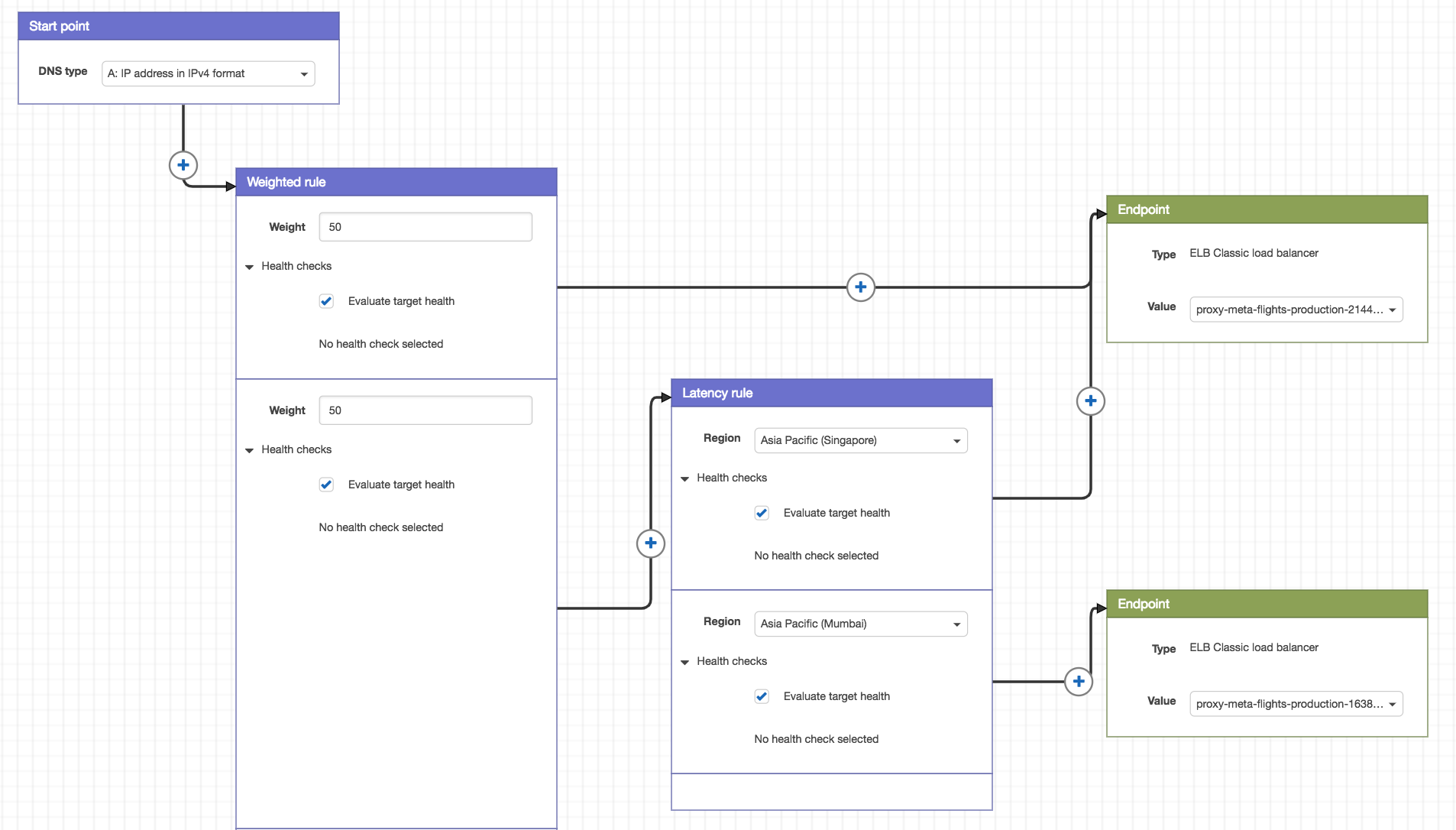
Referring to the traffic policy above, the weighted rule allows us to control its traffic in a granular fashion. We can simply assign different weights to the Singapore-only traffic and the multi-region traffic. This allows us to gradually rollout latency-based routing, which routes traffic to respective regions based on latency. The weighted rule mechanism also enables us to quickly rollback in case something goes wrong.
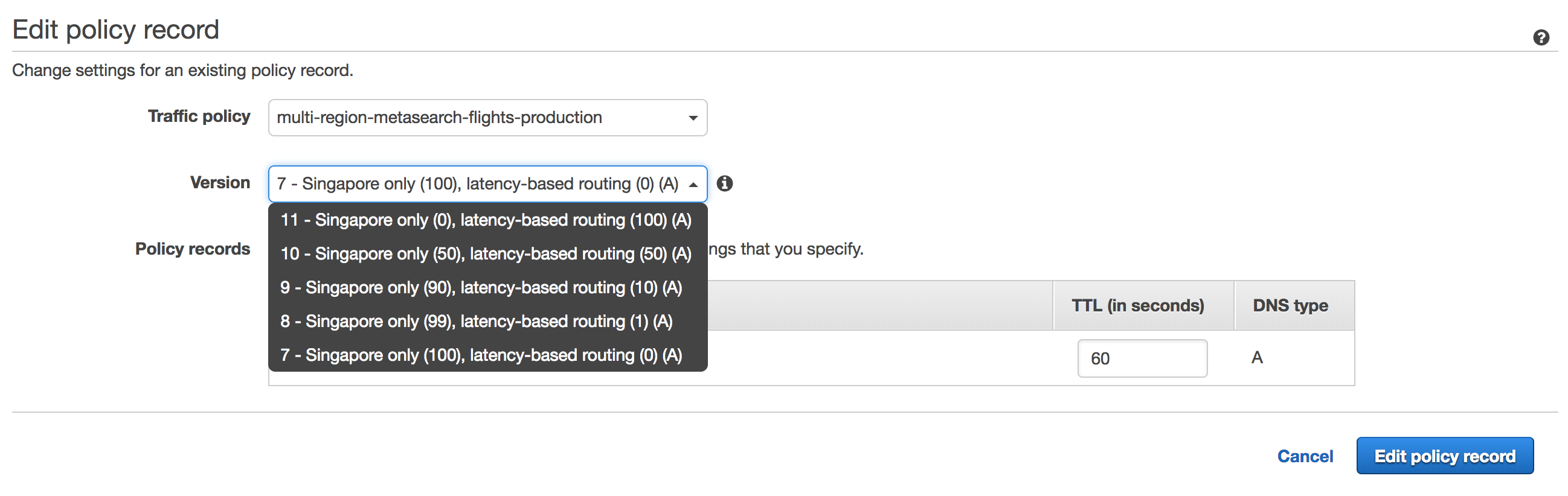
By making immutable versions of a traffic policy, we are able to smoothly rollout and rollback simply by choosing the right version.
To sum up, the request flow is visualized as:
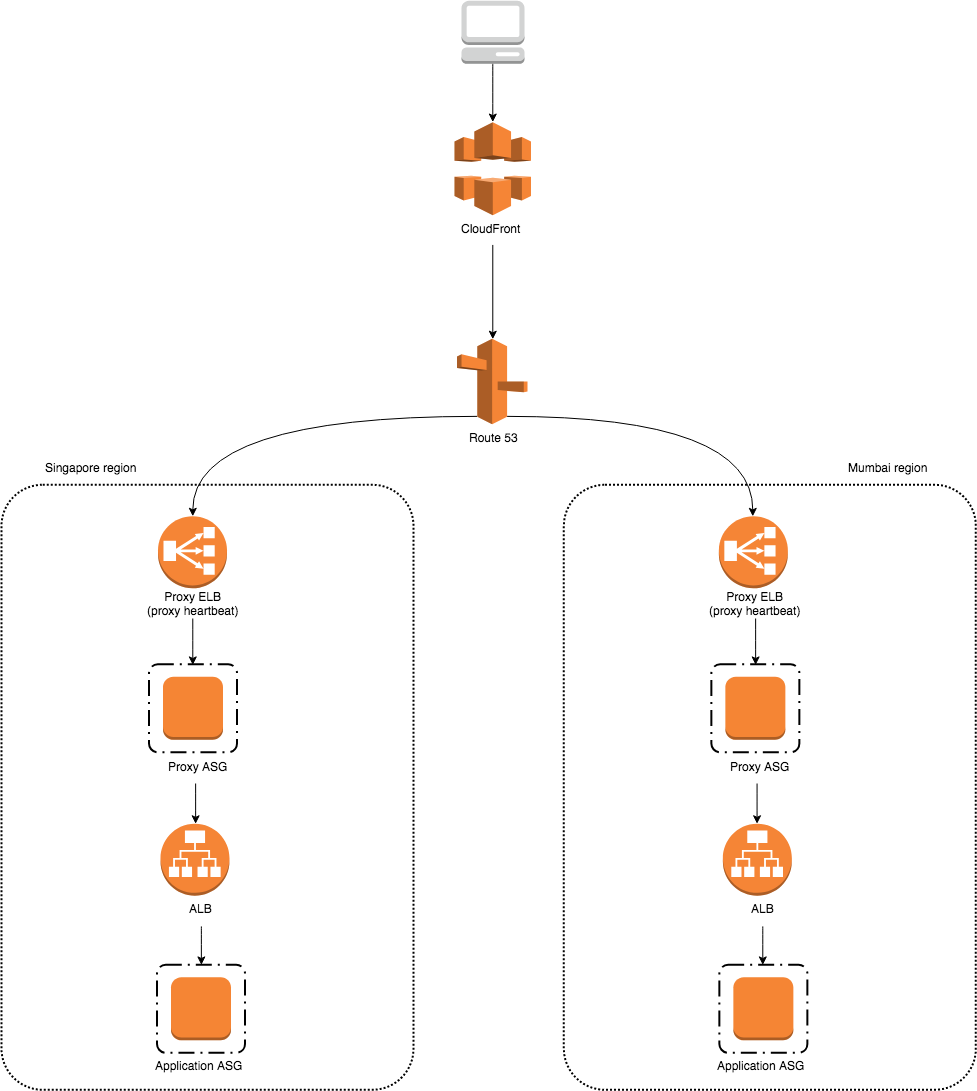
You might think that multi-region traffic engineering is all there is - routing of requests to respective regions based on latency. But that’s not all, its scope also includes automatic cross-region failover.
Automating Cross-region Failover
Route 53 can perform cross-region failover on the DNS level by detecting heartbeat failure for any of the endpoints. Assuming the traffic is split evenly between the two regional application clusters, can we perform cross-region failover if one regional application cluster is down?
Looking at the diagram above, it will not be possible. Route 53 is only aware of the regional proxy ELBs which listen to the proxy heartbeats. This means that cross-region failover will only take place if a proxy fails in one region. However, we want to do cross-region failover on the application layer, not the proxy layer. For example, we want to route traffic automatically to the Mumbai region if the application cluster in Singapore region is down. Right now, there is no way for the current regional proxy ELBs to detect the failure of a specific upstream service.
For companies that do not have proxies in front of application clusters, it is possible to just configure Route 53 to point to the application endpoints outright. Yet it is never a good idea to forgo proxies since they provide crucial functionalities such as rate limiting and authentication.
At Wego, we are using proxies heavily for our microservices architecture. We do not want to forgo proxies but at the same time, we want Route 53 to detect application heartbeats. The key insight is that proxies can also listen for application heartbeats. Since the proxies are there to stay, why not listen for application heartbeats through them? This requires us to create additional proxy ELBs to detect heartbeats for each multi-region application.
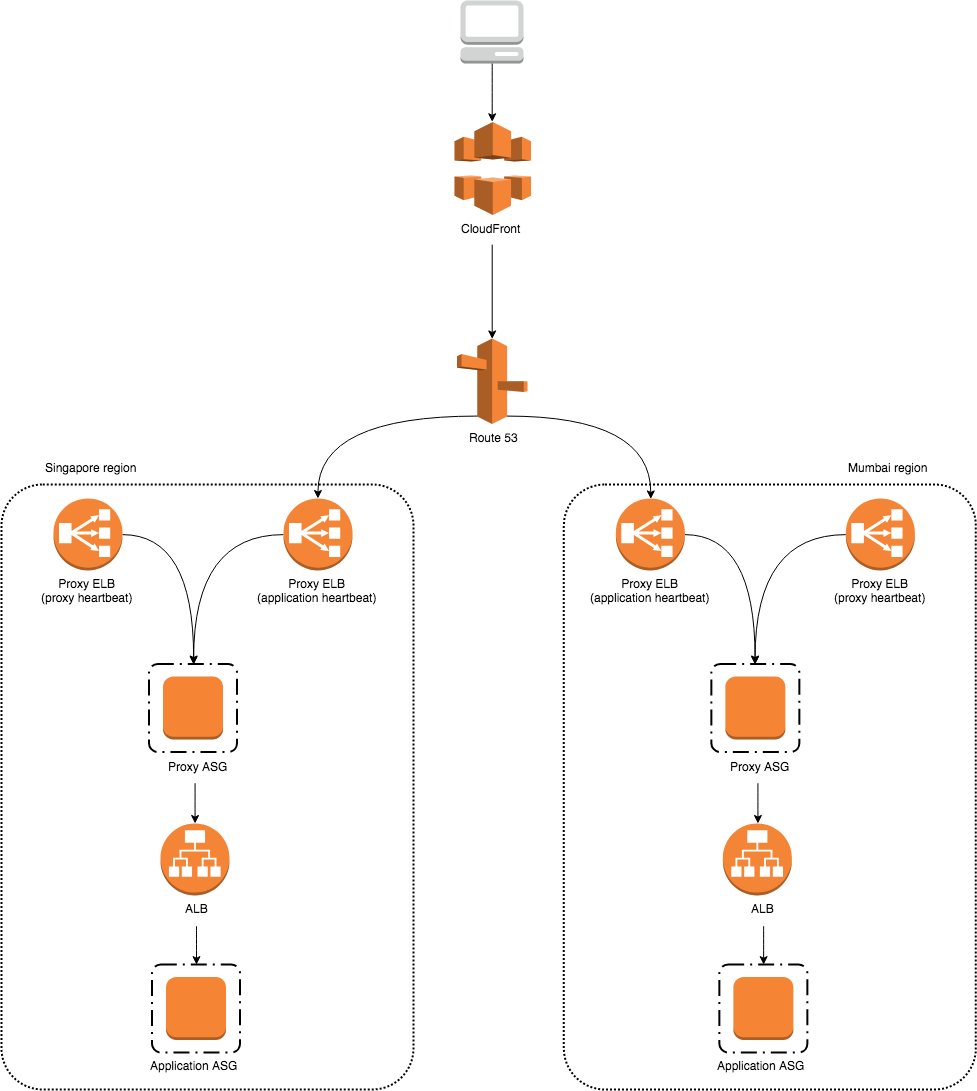
Concretely, for the traffic policy of a multi-region application, we replace the usual proxy ELBs with bespoke proxy ELBs that only listen for that application’s heartbeat. Even though Route 53 will not forward multi-region traffic to the usual proxy ELBs, they will still receive single-region traffic as before.
This solution is simple to implement; it requires no changes to existing infrastructure, it just extends it with additional ELBs. However, the drawback is the increased cost associated with the new ELBs. As the number of multi-region services increases, we need more proxy ELBs to listen for their respective heartbeats. This is obviously not cost-efficient and maintainable in the long run.
In our case, Wego’s multi-region roadmap only involves a small number of services. To test the waters of multi-region infrastructure, a simple architecture would suffice. If we want to expand our multi-region footprint down the road, we would need to revamp our architecture significantly. Sophisticated solutions like service meshes would be a good fit in that context.
Moving Forward
In this article, we talk about multi-region traffic engineering by focusing on traffic segregation and routing. These two mechanisms go hand in hand to achieve a clean separation of single-region traffic and multi-region traffic, as well as a granular control of the latter. Cross-region failover per multi-region service is achieved by a deliberate placement of bespoke ELBs that listen for a specific application heartbeat. This allows us to launch our multi-region project without extra maintenance overhead. As we continue with our multi-region efforts, we are continuously rebuilding our infrastructure as requirements change. If this sounds exciting to you, reach out to us, we’re hiring!
For other articles in the multi-region infrastructure series, please check out part 2 and part 3.
View Comments