What is Elasticsearch? We call it ES.
Elasticsearch is an open-source distributed search engine. It is based on Lucene and is capable of indexing schema-free JSON documents. It supports full-text search through its RESTful API. ES is easy to scale and can support near real-time search. As a distributed search engine, the indices can be divided into shards and can provide high availability by adding one or more replicas for each shard.
ES at Wego
As a travel metasearch, ES is the core of our search infrastructure. When a user triggers a search on our website or app, our search engine will send requests to our partners for the results. Then those results will be indexed into ES so that it will be available for querying. Our flights and hotels search have different ways of connecting into the ES cluster. Flights search connects using a client node, which handles and routes the requests to the ES cluster. On the other hand, hotels search utilises the RESTful API where the search queries are sent to ES using HTTP request. Flights and hotels search engines both have their own cluster. Each has indices that are composed of multiple shards and replicas.
We have been using ES for years and we think it's useful to share with you how we leverage ES at Wego.
What are the challenges?
Amount of data
For every single search request from users, we will have to send hundreds of requests to partner’s APIs and retrieving thousands of responses. The amount of data for each search is very big. We also have to keep the data in ES for a while for caching purposes.
Scaling
As a nature of distributed system, data rebalancing and recovering whenever adding a new node would normally take time.
Custom ranking
We want to provide the most relevant results to our users, using our historical search data as well as users' behaviour. The ranking data is produced by in the background jobs within our big data platform and we need to find a way to integrate this into the ES document's score.
Complicated data models
We have to deal with complicated queries to multiple indices such as hotels information ( location, reviews, amenities, etc), hotels ranking, live prices and aggregations. We, then, apply ranking and sorting algorithms.
To reduce the processing time from the client side, we have to move all of data manipulations to ES. The client will get everything in one-go by just one request to ES.
How do we build our ES cluster?
Native scripts
To solve the one-to-many relationship (one hotel has many rates), we also considered parent-child indexing but it wasn’t a very effective solution and we still have to implement our own custom ranking logic in some way. We have found that native scripts can help us to define custom score logic and fetching data from child index within the same query.
After that, we started an ES plugin and put all search related logic including sorting, ranking, filtering into the plugin. We solved the one-go challenge (one query to ES to get everything).
The response time was really impressive, it’s less than 200ms for almost all requests. For some really big destinations, it’s around 4-500ms. We reduced the response time from 1-3s to 200-500ms.
By removing the logic from front-end, the number of Rails servers was also reduced and are now much more stable.
Dedicated master nodes
ES ships with the default configuration which is enough to get you started to set up an ES cluster. However, when you are indexing a huge amount of data, the configuration values need some tweaking depending on your needs.
One of the major issues we faced is that during peak hours where the traffic is at its highest, some of the busy nodes will be unresponsive and there will be a failure of communication among the nodes within the cluster. When this happens, the unresponsive node will remove itself from the cluster and will elect itself as the master then creating a new cluster. Now there are two clusters that are indexing search results and accepting search requests from clients. This will lead to inconsistency of data and even worse when some data will be lost or corrupted. This issue is called the split-brain problem.
The split-brain problem can be solved by setting the configuration value discovery.zen.minimum_master_nodes using the formula (N / 2) + 1 where N is the number of master-eligible nodes in the cluster. In the event that one of the nodes in a cluster of four masters eligible nodes becomes unresponsive and gets out of the cluster, it will not elect itself as a master since (N / 2) + 1 or 3 master-eligible nodes are needed to elect a master node for the cluster.
Setting up dedicated master nodes is another way to maintain high availability of the cluster. By setting the configuration values node.master = true and node.data = false a node will become a dedicated master node. The dedicated master server will not accept any search request and will just sit there doing nothing except for maintaining the state of the cluster.
Optimised TTL (time to live)
Another issue we faced is that our cluster is indexing and storing a huge amount of data causing high CPU usage on our servers and high latency on serving requests unless we keep adding more servers. We realised that our live search results are already cached on our caching servers and in fact live results are only needed within a short period of time. So we decided to set the TTL (time to live) of the documents to a shorter period. This reduced the CPU utilisation on the ES servers significantly and faster response with low latency on the search requests.
Reduce unnecessary caching in ES
We have also reduce the filter indices.cache.filter.expire and field data indices.fielddata.cache.expire caching to match with the document’s TTL which also can free up the memory significantly.
100% uptime
We wanted to share the differences in term of CPU and latency at the time when we deployed new configuration, added dedicated master nodes, optimised TTL quite awhile ago. We have achieved 100% uptime so far for our Elasticsearch clusters.
The CPU of ES nodes for flights has been much more stable after optimising the configuration and now we can potentially reduce the number of servers.
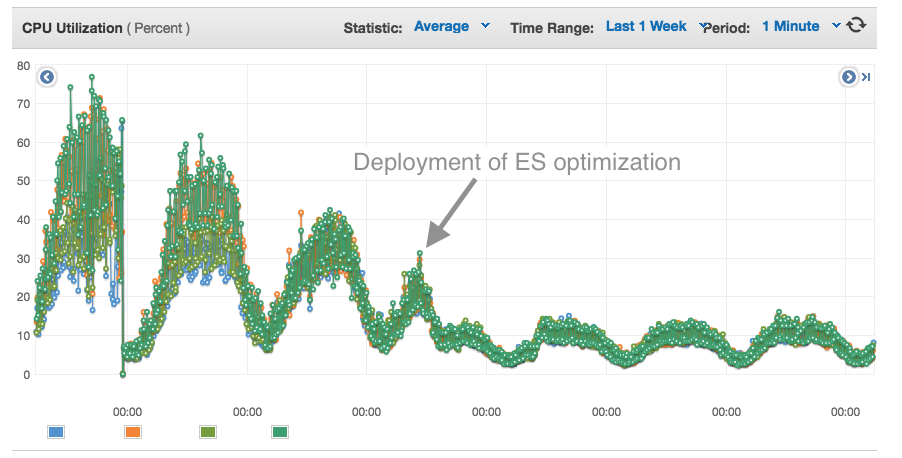
The latency is reduced significantly resulting to faster response time to search requests:
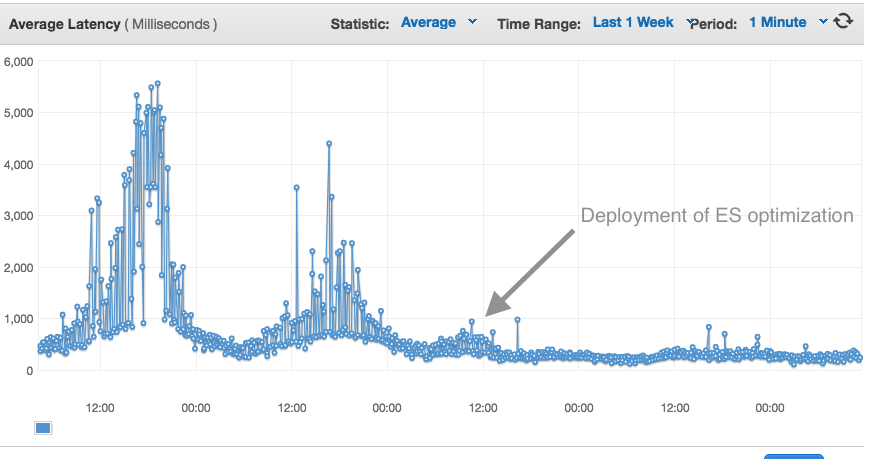
Scaling ES is a pain and we spent some considerable amount of time monitoring and tweaking up the configurations in order to achieve a high-performance search engine. Until now we are very happy with our backend and never had to wake up at night anymore.
We are solving problems, constantly improving our platform to serve our users better. We love building things, making meaningful impact.
Also, we're hiring!
View Comments