Migrating to GCP Composer from Self Managed Airflow
Scroll DownThis article details the whole migration process on moving away from self hosted airflow to Composer, a managed service offered by GCP. But why?
- Workloads are hosted in different region.
- Moving towards a containerized environment.
- Sunset redundant tools and features like Jenkins and ssh operators based DAGs.
- To secure by hosting it as managed airflow privately.
Let's look in depth about how the composer was set up in Wego.
Data Science Composer is created in a private environment and does not have direct access to the internet. There are lots of work parts within the composer which are available here to learn. At the time of creation, GCP provisions and manages all the necessary components needed. All we have to do is to provide,
- Name of environment
- Node Size/count
- Region
- Type of network
Newly created Data science environment looks like below.
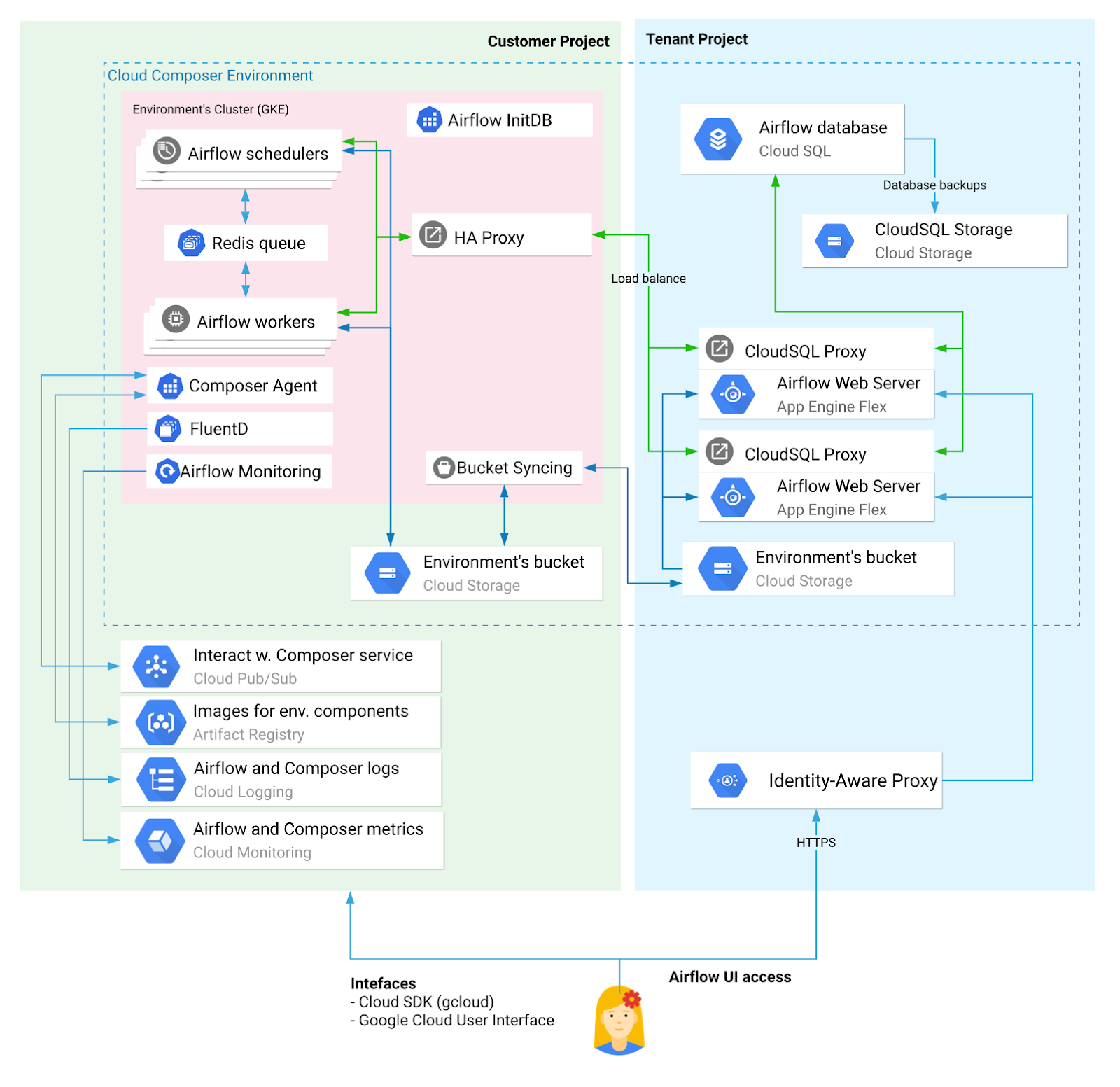
Data Science Workflow

How do we sync our DAG files?
Previously we pushed files via cron jobs on schedule to scheduler node. Here in the composer we use, Cloud Storage stores DAGs, plugins, data dependencies, and Airflow logs. When you upload your DAG files to the /dags folder in your environment's bucket, Cloud Composer synchronizes the DAGs to workers, schedulers, and the web server of your environment. These DAG files are hosted in GitHub and synced via Github Actions workflow.
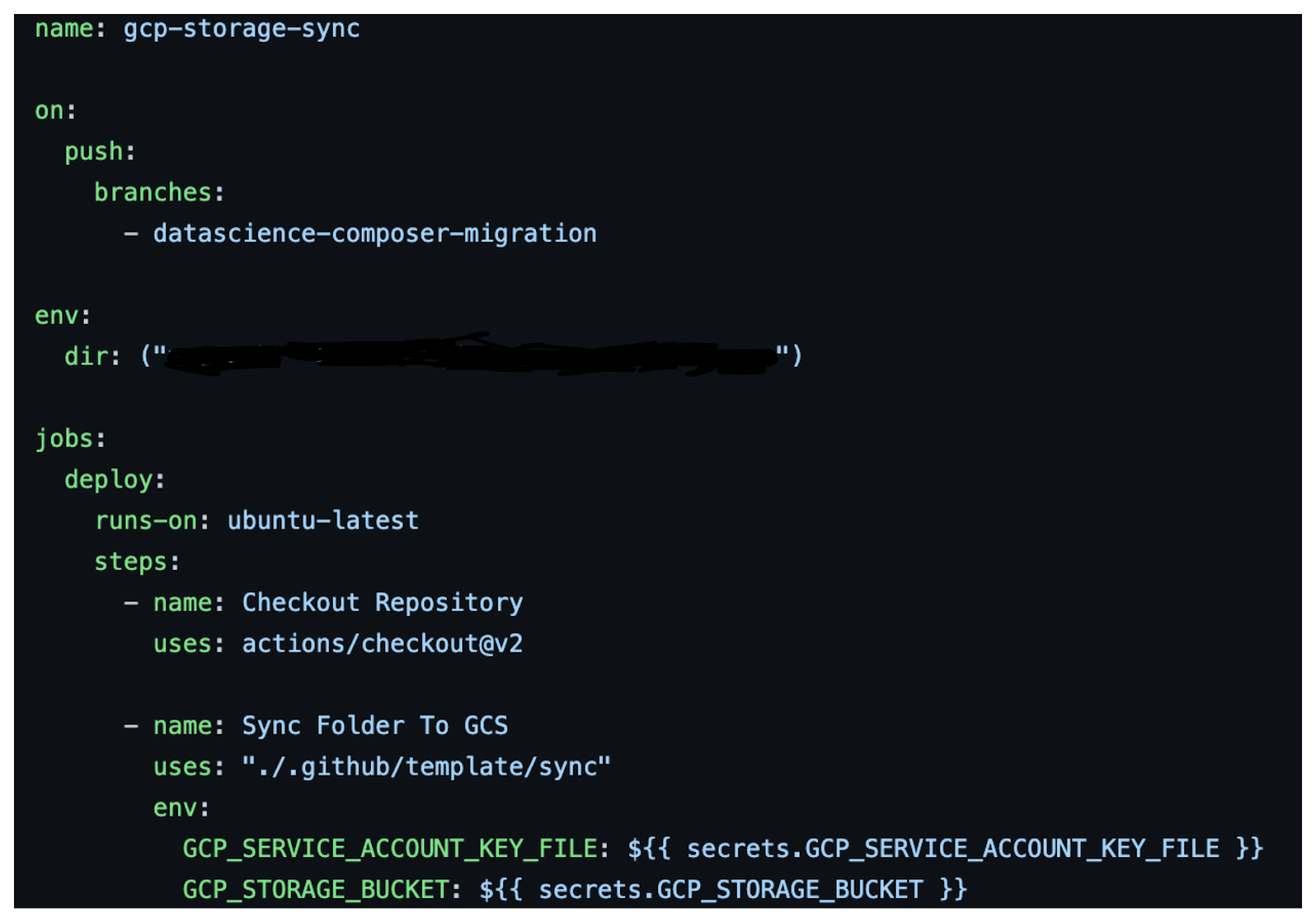
the above workflow will invoke the image google/cloud-sdk:alpine per Dockerfile running below entrypoint file to sync dags to GCS.

All the variables are defined in workflow.yml is stored under repo, setting > secrets > actions > repository secrets
How do we push images?
Ansistrano module (ansible) was used to push files of DAG specific code/dependencies to worker node. Jenkins pipeline job was used to create all the necessary templates along with code and push those files to a specific directory which in turn is created as a symlink.
This whole deploy workflow has been replaced and separate data science jenkins which was responsible for ansistrano based deploy has now been made redundant. Build pipeline has been migrated to existing main Jenkins reduced to 3 Jobs from its previous 7 (parameterised DAG triggers and ansistrano based deploy etc., are no longer needed).
Note: This exercise help us effectively use compute resources, and move our resource being exposed publicly to private zero trust based network
Images are built from main Jenkins (on ZTN) and are stored in the Artifact registry required for DAG to run at scheduled times.
Using the Kubernetes Pod Operator, pods are launched into the Google Kubernetes Engine data science cluster environment. SSH operator and its functions within all the DAGs have been re-coded with k8s pod operator to use operator.py.
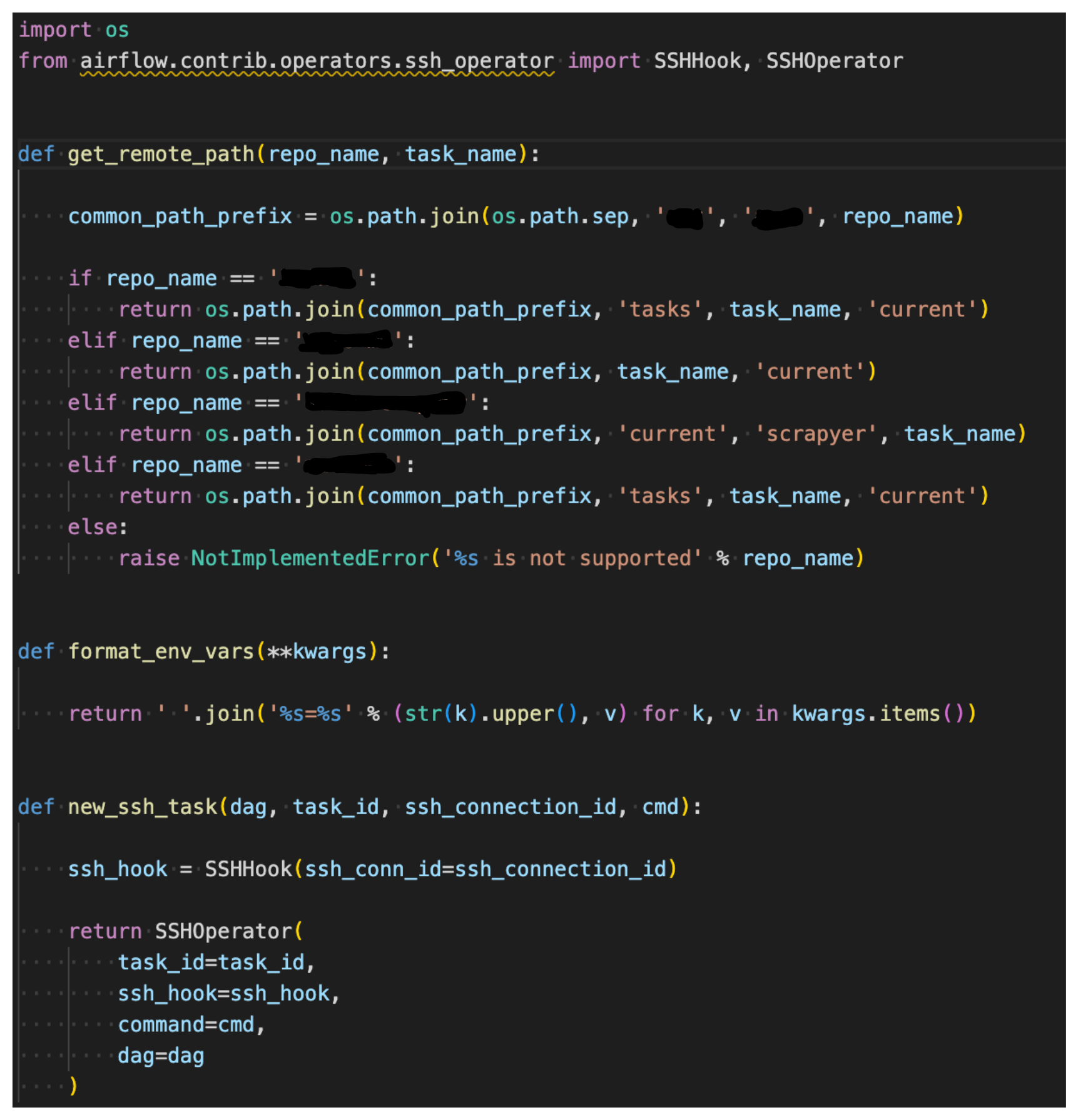
SSH operator will get inside the worker node's task path and execute the command passed by the new_ssh_task function of the running DAG. In the case for pod operator, it pulls the images and runs the command fromnew_kubernetes_task with defined pod_resources.
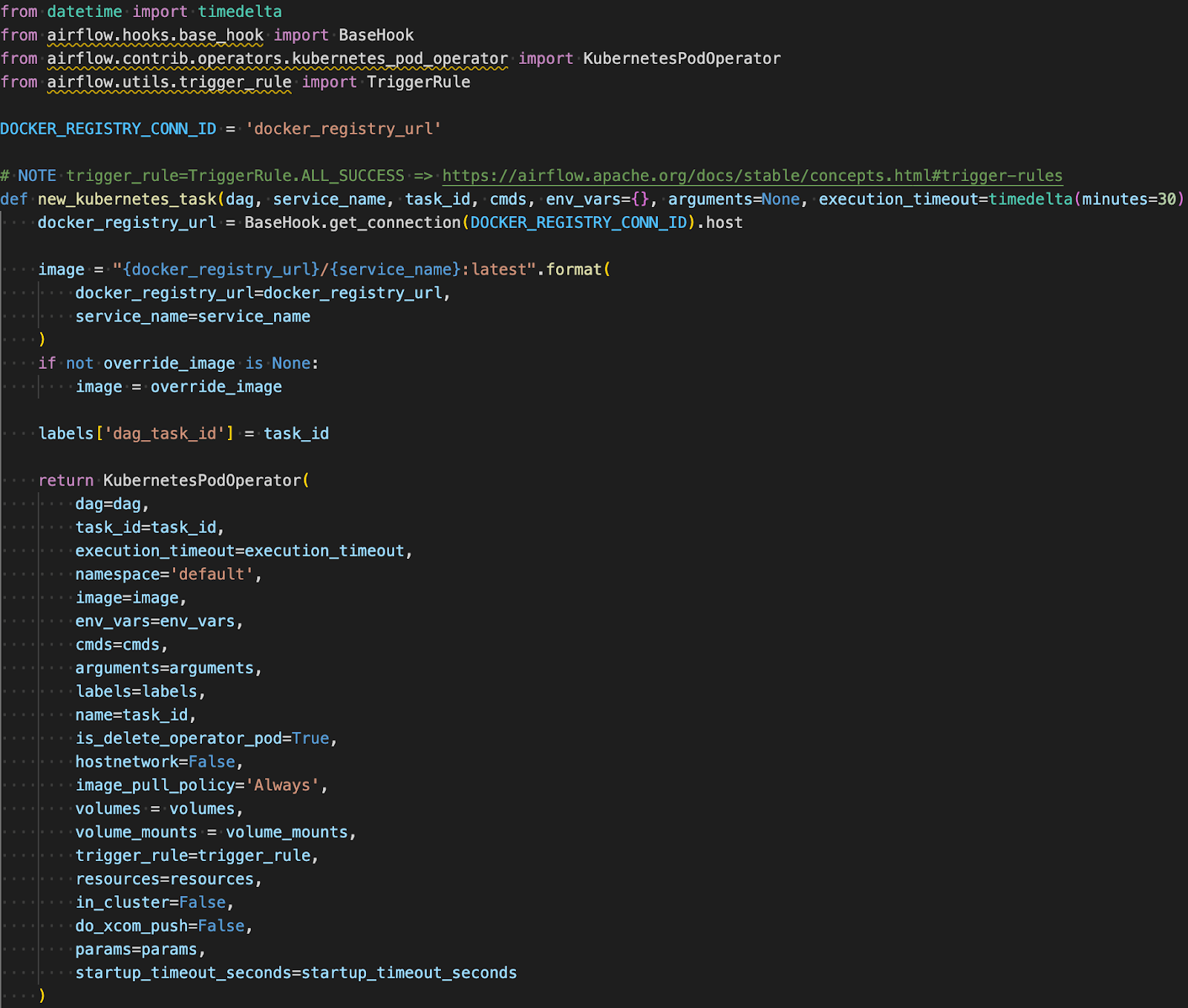
This switch ensures each DAG runs in an isolated matter as opposed to an SSH operator where it is just like a linux command.
How does it access the internet?
DAGs dependencies required them to access the internet, where Cloud NAT is used to create outbound connections to the internet from a subnet in the data science composer hosted region.
Summation
These migration leaves more scope/opportunity to further improve the system.
- DAGs with python 2.x version be migrated easier to python 3.x.
- upgrade the airflow version from 1.x to 2.x
View Comments