Rake is popular utility in Ruby's extensive tool set. It has over time become a standard to run repeatable tasks, be it from migrations in Rails to data processing/migration/manipultaion. In short if you have a task to automate, rake it.
We use ruby extensively in our services and have a team experienced with the language. As we have to do a lot of processing of different data, Rake is used extensively. We have AWS EC2 instances that are maintained by different teams and are what you can call job servers. One of those servers is for data related jobs called Analytics Tasks. It is the server that was initially setup to run data migration from AWS S3 to Google BigQuery. At the start there were around 24 jobs running every hour and it was a c4.large instance, performing well. Over time the number of jobs increased to over 60 and the instance grew to a c4.2xlarge. In early 2018 we upgraded our batch data pipeline to a steam version as an ELT, with that we started uploading data down to 2 minutes for some data set and on average 5 mins for all. As data was being streamed and with eventual consistency model of cloud storage we added hourly checks for all our datasets which meant more processing power was required as the number of task grew to over 700 per hour, hence the instance grew to a c4.4xlarge. As it is with every growth that bottlenecks are bound to happen and we started to see peak usage at points when data from the batch and stream pipeline both were overlap for uploads.
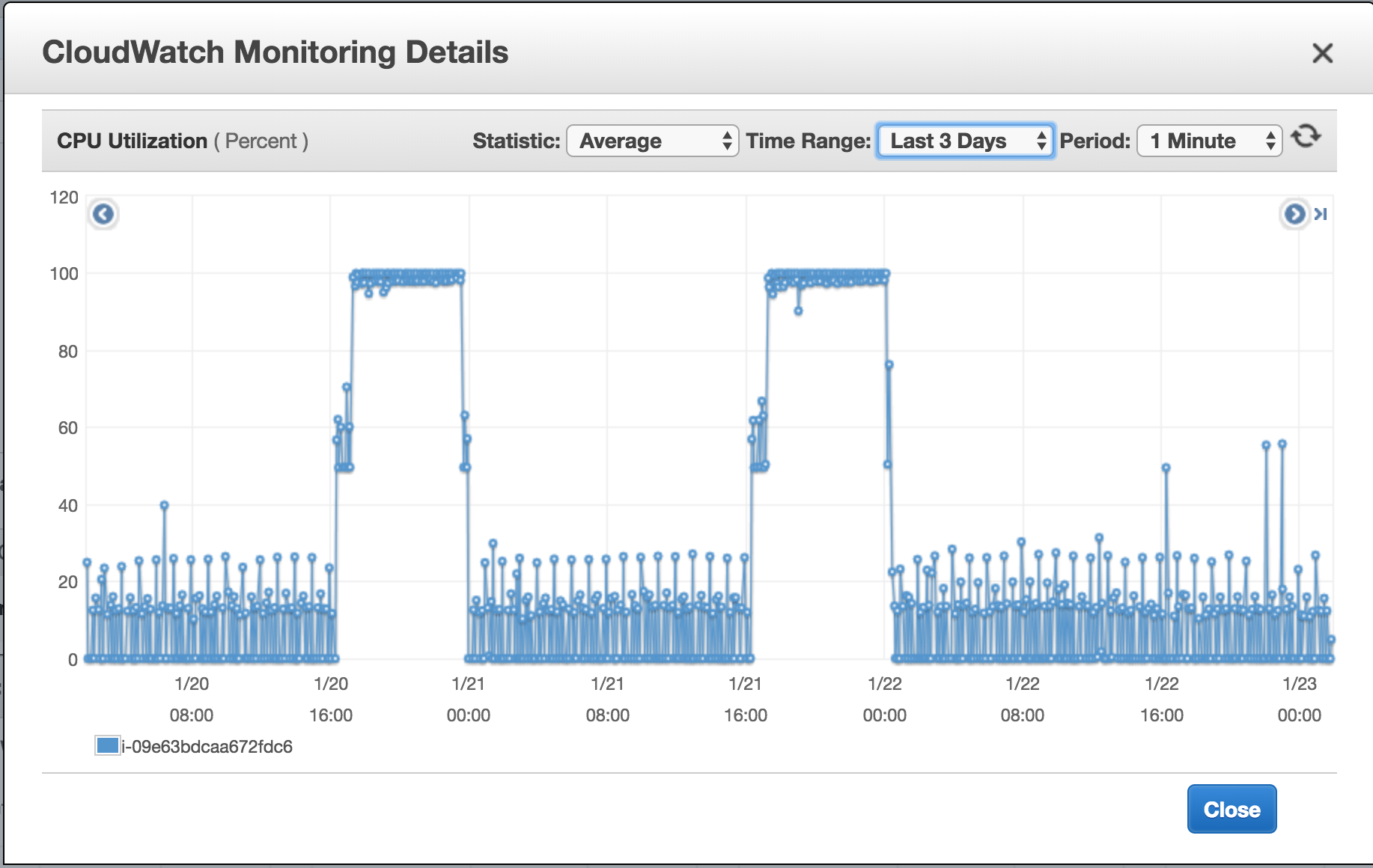
As evident these were long running peaks, alerting of eventual failure at any point. The first change that was added to the system was to replace gsutil from the old logic to retrieve list of objects to be uploaded to BigQuery with calling the Google API for GCS , this replaced a process invocation per task and released resources that were being reserved every time gsutil was invoked. After this change we saw the peaks fall down resulting in stable performance over the c4.4xlarge
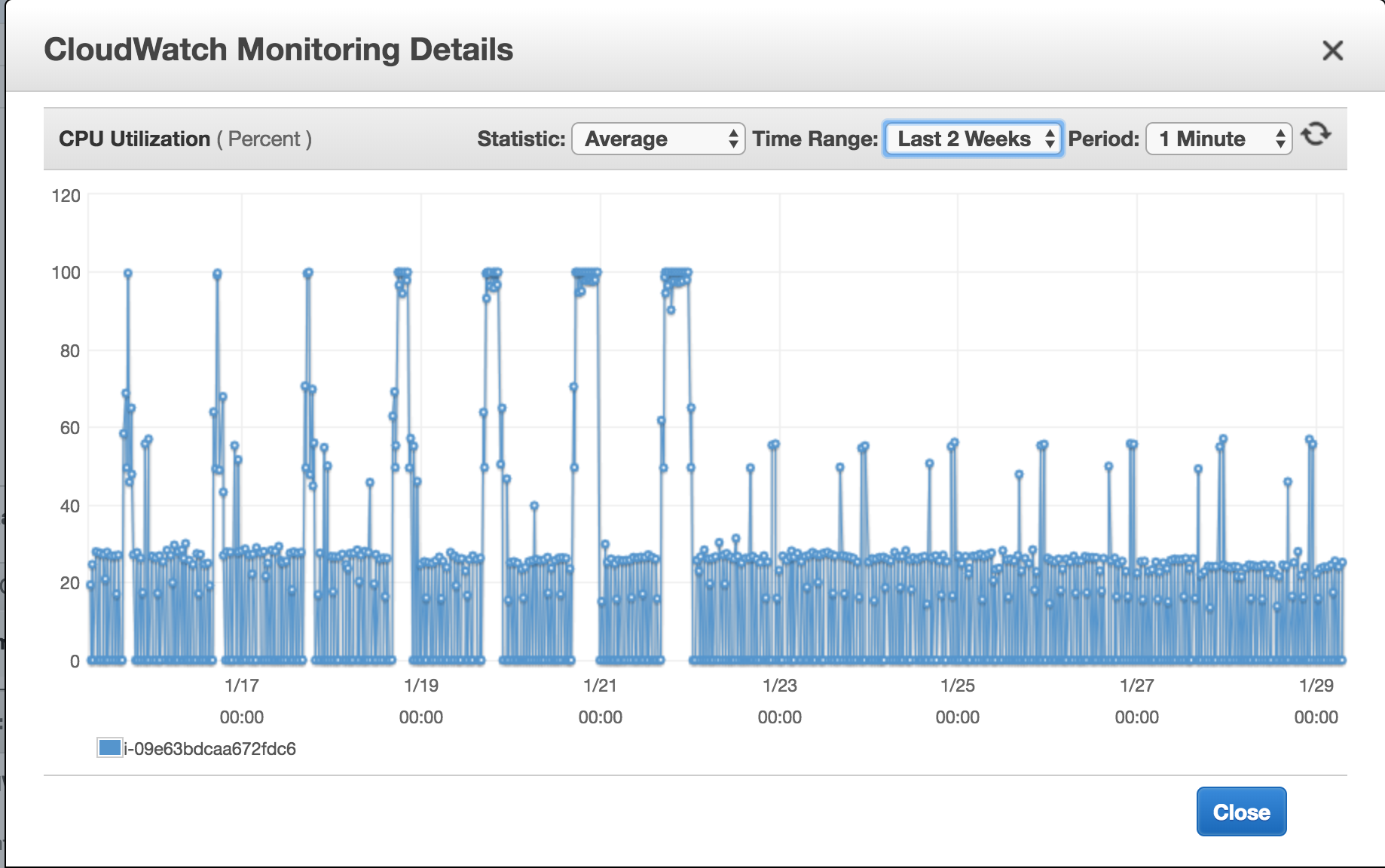
This learning gave birth to the realisation that most of the resource intensive CPU usage is by rake which itself initiates a process per task and by this time we had close to 900 tasks running every hour. So it was decided to replace rake per task and use it as per frequency, what does that mean ? Rake is great and we were running task at equal intervals so we have different dataset upload frequency some upload every 2 mins, other 5, 10, 15, 30, 60 mins, so looking at that it was simple matter of running rake tasks at those intervals, down from 900 rake tasks we came down to around 7 rake tasks per hour, but we can't queue up to run 900 data uploads in queue. For that each task interval is multi threaded which means each data upload happens in parallel, every rake runs a task per thread and we have a thread pool to avoid generating too many threads per interval. Few things that saved us a lot of time upgrading the working model of the server was having tasks designed to have configuration files and have loose coupling between rake and the task. After these changes we were able to downgrade the server from a c4.4xlarge back to a c4.large. In process that is on its own a saving of over 5000 USD a year for just one server.
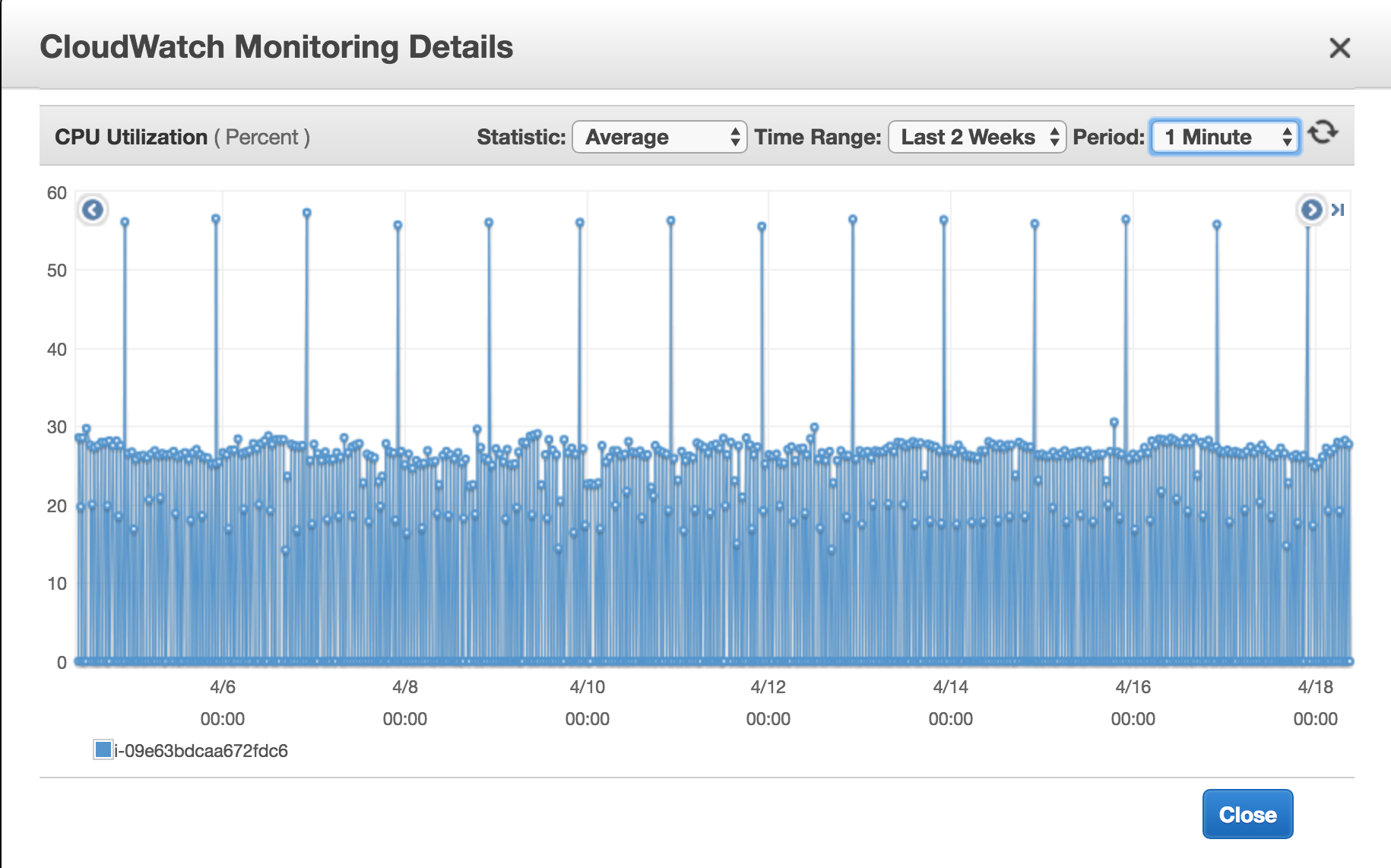
We always believe good coding practices and well thought out design go a long way. We are always looking to improve by learning from our work. Along the way if you can write sustainable code and save money, can't beat that combination.
View Comments