APIs have become a rising web standard with an increase in client apps ranging from Web to mobile apps. At Wego our analytics API has been at the core of delivering value to the user and business at the same time. Around 2 years ago we improved the initial implementation by doing a rewrite as v2, you can read all about it here. After improving speed and optimizing bandwidth we add insight into incoming data with the real-time tests on the analytic event stream on our staging environment. To give brief catchup on the history of our Analytics API to understand why we have decided to move to use MSON and JSON Schema to develop v3 of our API. The v1 was written around 2015 and it used Google's Protocol Buffers also known as Protobuf. At that time it seemed like a good approach by defining schemas and then generate typed classes for a multitude of classes (there is no ruby support available in protobuf2). It worked well for our metasearch APIs written in Java. For Ruby and our Analytics API, it became a pain point over time. First of all, we weren't using Protobuf for its intended use in any case for intercommunication in place of JSON. rather it was being used to create objects from JSON to a protos object and then back to JSON for logging. This was a major cause of v1 slow performance and to make the improvements v2 was done to make it async (which should have been the way in any case) though it mitigated the speed issue allowed us to stop using 3rd party analytics and rely solely on in-house data collection. To put things into perspective below is how protobufs are to be used and how they were being used.
How to use

How it was being used
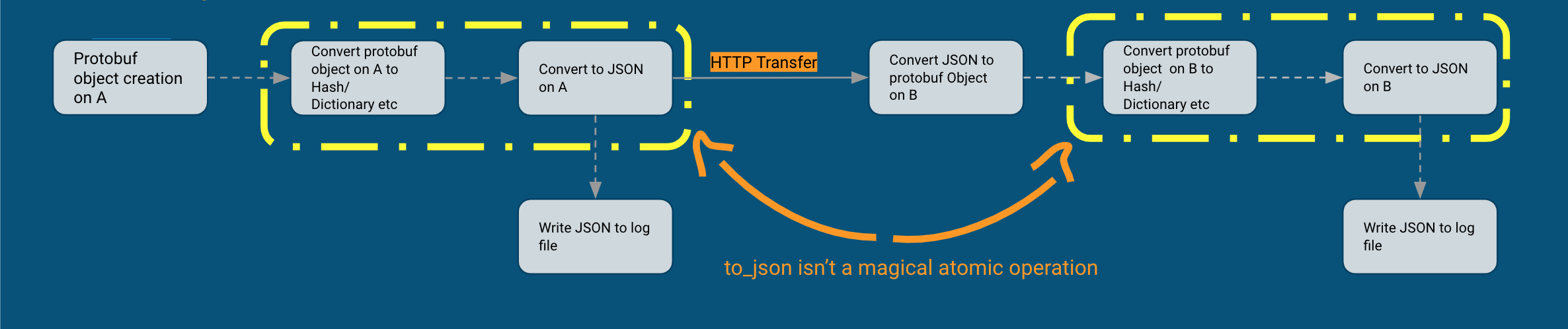
The pains of protobuf for us didn't stop at the API level. We upload our data to Google BigQuery via our ETL pipeline and being able to generate BQ schema from the same Schema file sounds great. But over-abstraction of types caused clutter that would get introduced among services such as search object being used by metasearch is also used in analytics but over time the object has grown based on its use for metasearch which now introduces fields that are not required in analytics or other services causing bloat not only at the API for the object but also add empty columns to BQ tables. The pains of protobuf are well explained in this article states well about the required filed that has burned us the most on API and BQ level due to numerous hacks we have in place to make the protobufs work for Ruby.
The most problematic of these is the required type. Google explains it best:
Required Is Forever: You should be very careful about marking fields as
required. If at some point you wish to stop writing or sending a required
field, it will be problematic to change the field to an optional field – old
readers will consider messages without this field to be incomplete and may
reject or drop them unintentionally. [...] Some engineers at Google have come
to the conclusion that using required does more harm than good; they prefer
to use only optional and repeated.
So that was a quick rundown of our and use of protobufs vows. For v3 we decided to standardize the process of adding events rather than continue to use protobufs to dictate the events types and then get blindsided by the incoming changes. To start working on an event type it has to be documented in API Blueprint the reason to pick it is its first class support in Github for syntax highlighting, the ability to define the request object as MSON in it and the number of tools available to work with JSON, JSON schema along with testing and mocking an API. Once we have a documented API with MSON defined request attributes and sample body object defined in JSON we can generate JSON schema and BQ schema which is consistent.
To generate the JSON schema we use apib2json which allows us to use our apib docs to generate the JSON schema. It comes with a docker container to run the process allowing no dependency hell. We use jq to extract the schema object for it to use with our ruby code base via json-schema
docker run --rm -i bugyik/apib2json --pretty < input.apib | jq -r '.[] | .[] | .schema' > output.json
Similarly, for BQ schema we have two approaches to use based on how flexible we need the schema to be. If we need the constraints defined in MSON to be transferred to BQ schema we have to use JSON schema other wise for a flexible schema with no constraints use the JSON object based on apib doc. For both , I have open-sourced docker container packages jsonschema2bqschema (if you are interested in how v3.0.0 for jsonschema-bigquery got released upon which this docker container relies on view this issue and PR27 of mine to give you some insights) and json2bqschema that can be used for ease of the process and let the developers not worry about dependencies of generating BQ schemas.
docker run --rm -i darahsan/jsonschema2bqschema < input-file.json > output-file.json
docker run --rm -i darahsan/json2bqschema < input-file.json > output-file.json
One might think at this point that what about the typed classes benefit that protobuf had as the objects can become complex and managing code for them can become tiresome with continuous updates. By standardising our JSON object with JSON schema it gives us the option of using quicktype to generate typed classes from the same JSON schema that is documented in apib and defined as MSON in it.
To simplify the process for generating typed classes using quicktype from command line a docker container package is open sourced for convenience as it has multiple dependencies if to be setup by each individual per team. The package source is available at jsonschema2quicktype and can be used as follows
docker run --rm -i -e QUICKTYPE='-l <supported-language>' darahsan/jsonschema2quicktype < input-schema.json > output-class.ext
We hope to standardise the process from documenting the API to using a single standard from communication to validating and processing data will avoid issues in future.
View Comments